
Redis 提供了丰富的数据类型,常见的有五种:
- String 字符串
- List 列表
- Hash 哈希
- Set 集合
- Zset 有序集合
随着 Redis 版本的更新,后面又支持了四种数据类型:
- BitMap (2.2)
- HyperLogLog (2.8)
- GEO (3.2)
- Stream (5.0)
在线 Redis 体验 → https://try.redis.io/
🦮 String
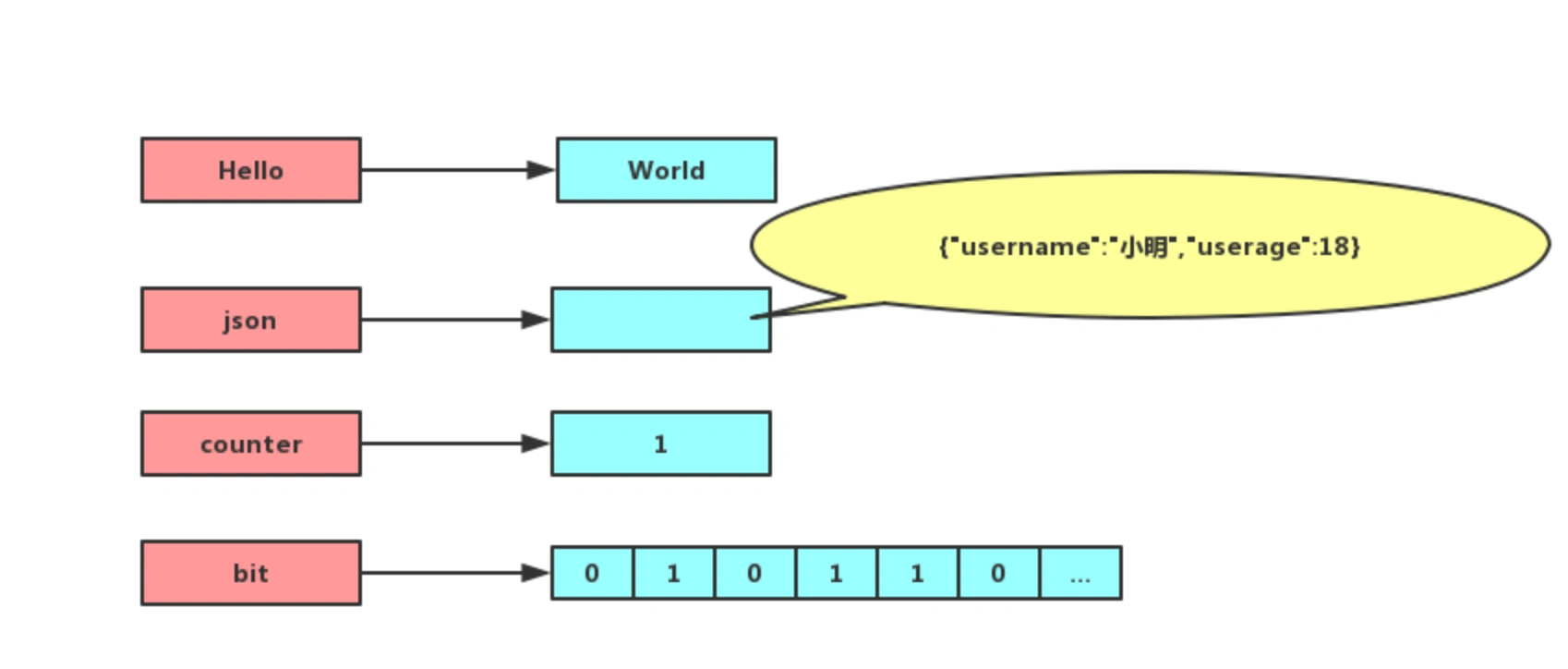
String 是最基本的 key-value 结构。key 是唯一标识(可以是字符串、数字),value 是具体的值(最长可以容纳 521M)。
🎗️ 常用命令
- 🧩 基本操作
| |
- 🧩 批量设置
| |
- 🧩 计数器(value 为整数)
| |
- 🧩 过期(默认为永不过期)
| |
- 🧩 存在与不存在
| |
🎡 实现方式
String 的底层实现是自定义的 SDS(简单动态字符串)。
相比于 C 语言的字符串:
- SDS 不仅可以保存文本,还可以保存二进制数据(如图片、音频、视频等)。
SDS 的 API 都会一处理二进制的方式处理保存在 buf[] 数组中的数据。
- SDS 获取字符串长度的时间复杂度是 O(1)。
C 语言的字符串不会记录自身长度,获取需要遍历,时间复杂度为 O(n)。SDS 结构中记录了长度。
- SDS 的 API 是安全的,拼接字符串不会导致缓冲区溢出。
SDS 在拼接前会检查空间是否满足要求,不够的话会自动扩容。
🧵 使用场景
📐 缓存对象
- 直接缓存 JSON。
SET user:1 '{"name":"emery", "age":18}' - 分离为 user:id 作为 key,用 mset 存储。
MSET user:1:name emery user:1:age 18 user:2:name lin user:2:age 20
- 直接缓存 JSON。
📐 常规计数
Redis 处理命令是单线程的,所以执行命令的过程是原子的。可以对访问访问次数、点赞、转发、库存数量进行统计。
| |
- 📐 分布式锁
NX 参数可以实现在 key 存在的时候,才插入数据,可以用来实现分布式锁。
| |
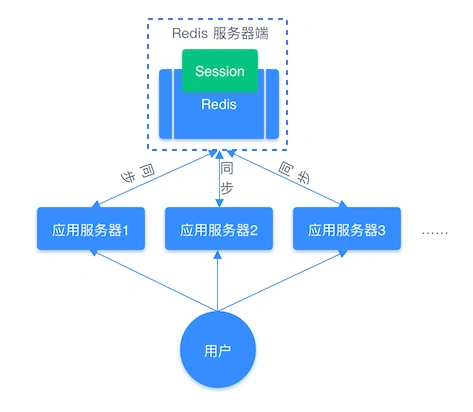
- 📐 共享 session 信息
Session 保存在服务端,通常用于保存用户的会话状态(登录)。
在分布式系统中,用户多次请求不一定都在同一台服务器中,我们可以借助 Redis 对 Session 信息进行统一的存储和管理,服务器都去同一个 Redis 获取相关的 Session 信息,这样就解决了分布式系统下 Session 存储的问题。
🐅 List
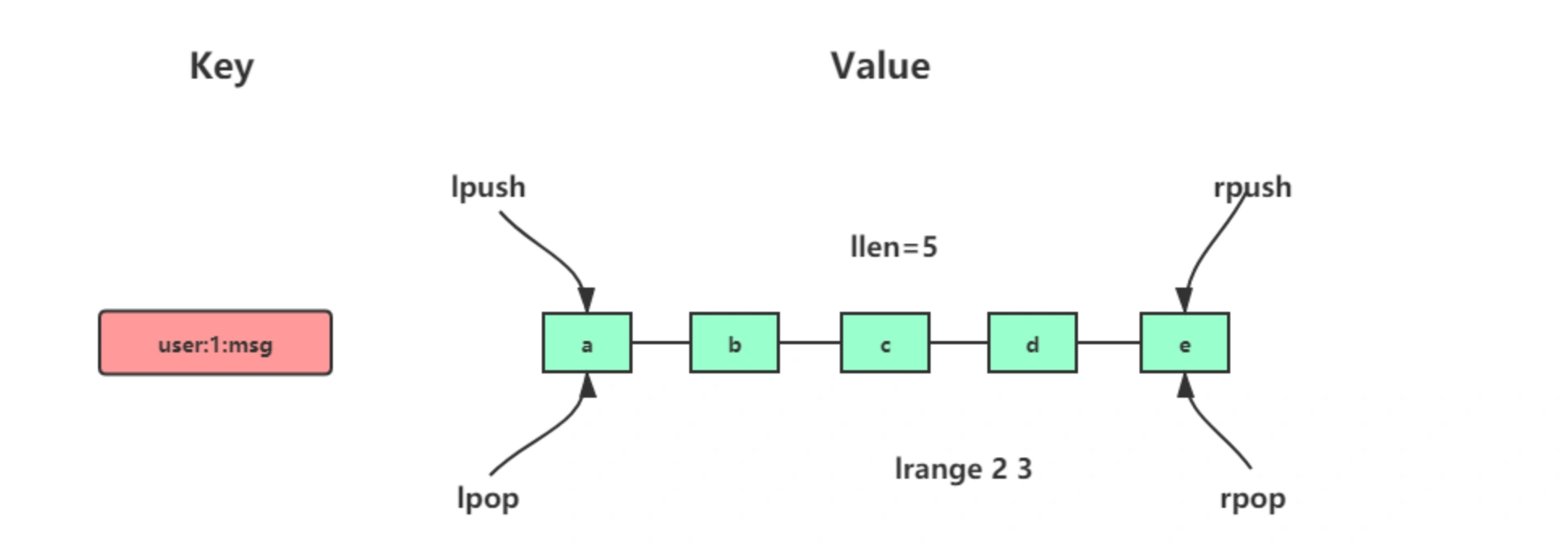
List 是简单的字符串列表,按照插入顺序排序,可以从头部或尾部向 List 中添加元素。最大长度为 2^32 - 1。
🎗️ 常用命令
| |
🎡 实现方式
Redis List 底层由(1)压缩列表 或 (2)双向链表 实现。
压缩列表:
- 如果列表的元素个数小于 512 个(默认值,可由 list-max-ziplist-entries 配置),
- 列表每个元素的值都小于 64 字节(默认值,可由 list-max-ziplist-value 配置),
- Redis 会使用压缩列表作为 List 类型的底层数据结构。
双向列表:不满足压缩列表的条件底层就会使用双向列表。
压缩列表
是 Reids 为了节约内存而开发的,由连续内存块组成的顺序型数据结构,有点类型于数组。
在表头有三个字段: (1)zlbytes:压缩列表占用的内存字节数; (2)zltail:列表尾的偏移量(尾部距离首部有多少个字节); (3)zllen:压缩列表包含的节点数量;
在表尾有一个字段: (4)zlend:列表结束的标志(固定值 0xFF -> 255);
查找定位第一个和最后一个元素的时间复杂度为:O(1) 查找其他元素,只能逐个查找,O(n),所以压缩列表不适合保存过多的元素。
在 Redis中,List、Hash、Zset 对象,在元素数量较少,元素值不大时,会使用压缩列表作为底层数据结构。
🧵 使用场景
- 📐 消息队列

🦛 Hash
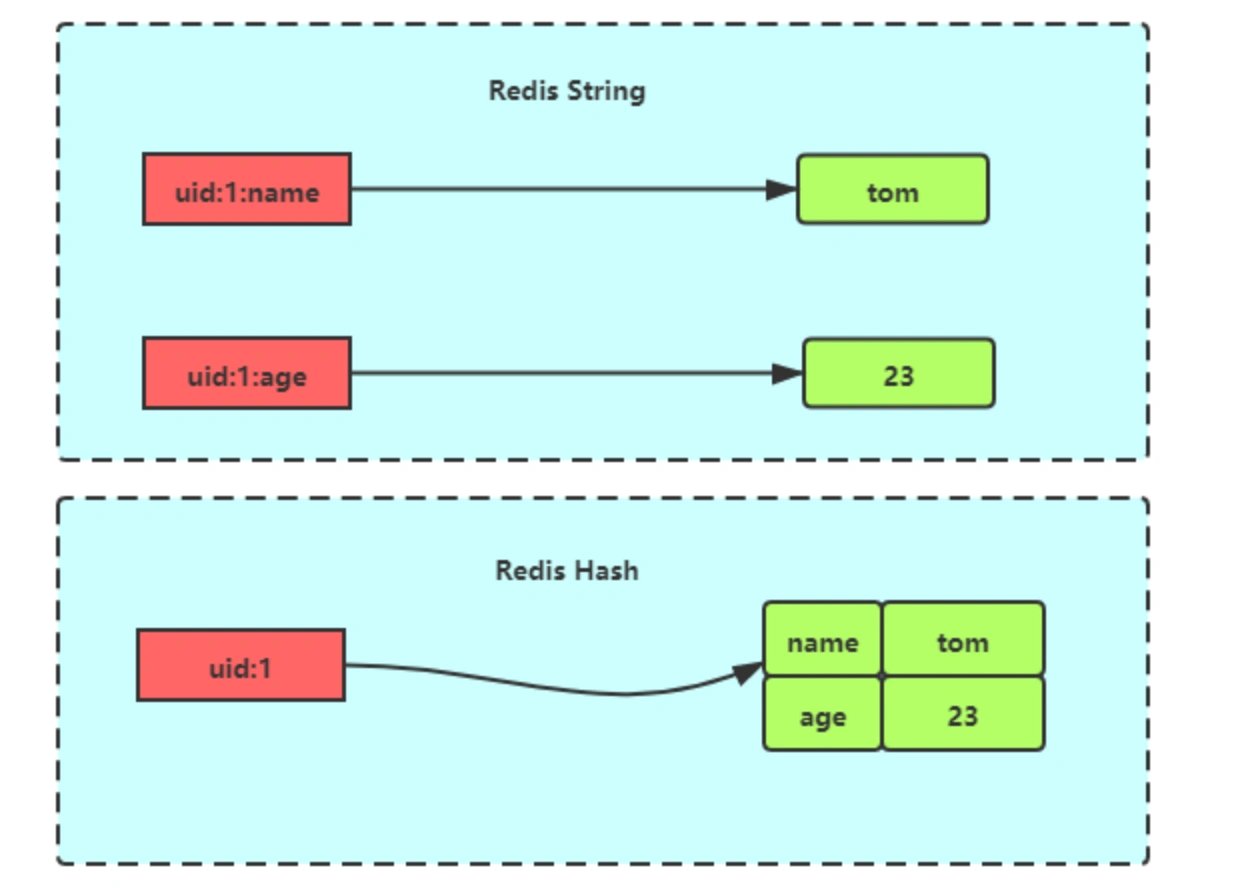
Hash 是一个键值对的集合 key-value,特别适合存储对象。
🎗️ 常用命令
| |
🎡 实现方式
Hash 类型的底层数据结构由 (1)压缩列表 或 (2)哈希表 实现。
压缩列表
- 元素小于 512 个
- 所有的值小于 64 字节
- 使用压缩列表
哈希表
- 不满足以上条件使用 hash 表
🧵 使用场景
- 📐 缓存对象
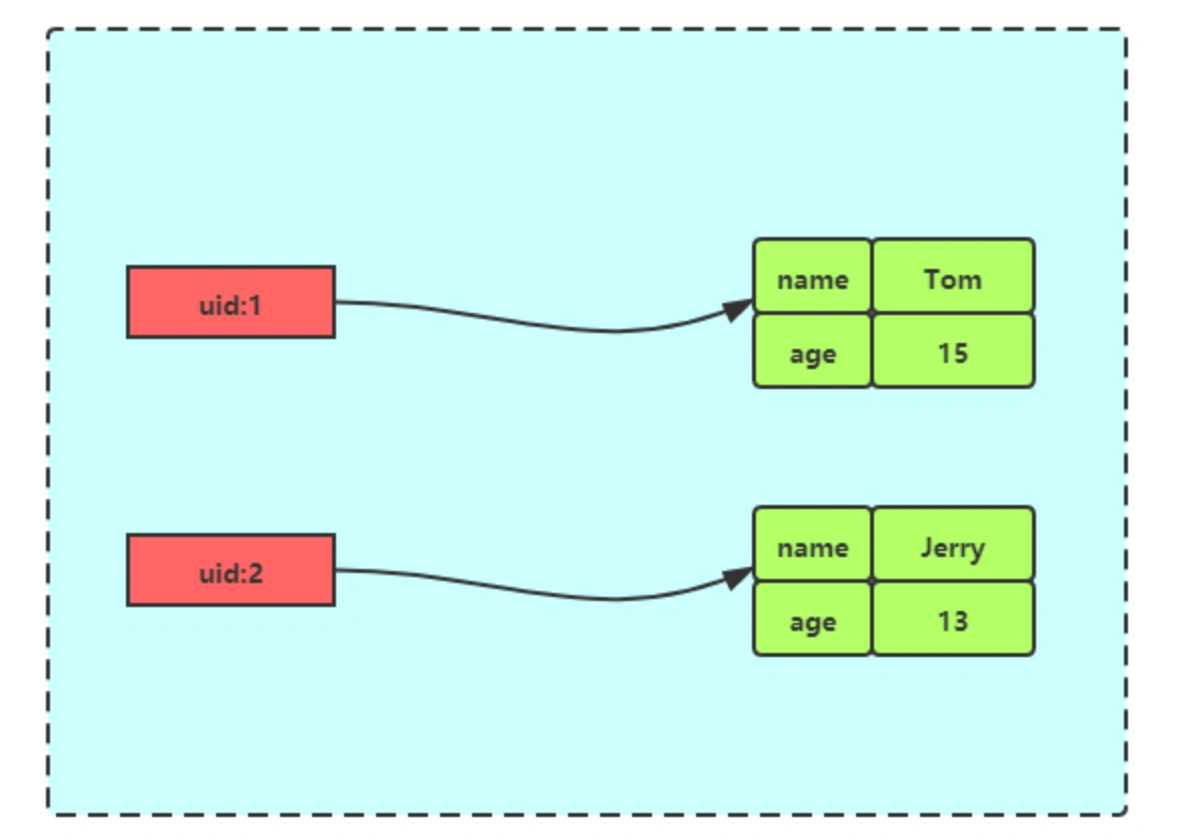
| |
使用 String 类型缓存 JSON 也是缓存对象的一种凡是,如果对象中某些属性频繁变化,可以考虑使用 Hash。
- 🛒 购物车
- 😃 用户 id -> key
- 🏪 商品 id -> field
- 🔢 商品数量 -> value
| |
在实际业务中,Redis 中只存储了商品的 id 信息,在回显商品的具体信息时,再拿商品 id 查询一次数据库,获取完整的商品信息。
🐑 Set
Set 是一个无序并唯一的集合(存储顺序不会按照插入的先后顺序进行存储)。
集合中最多可以存储 2^32 - 1 个元素,除增删改查外,还支持多个集合的交集、并集和差集。
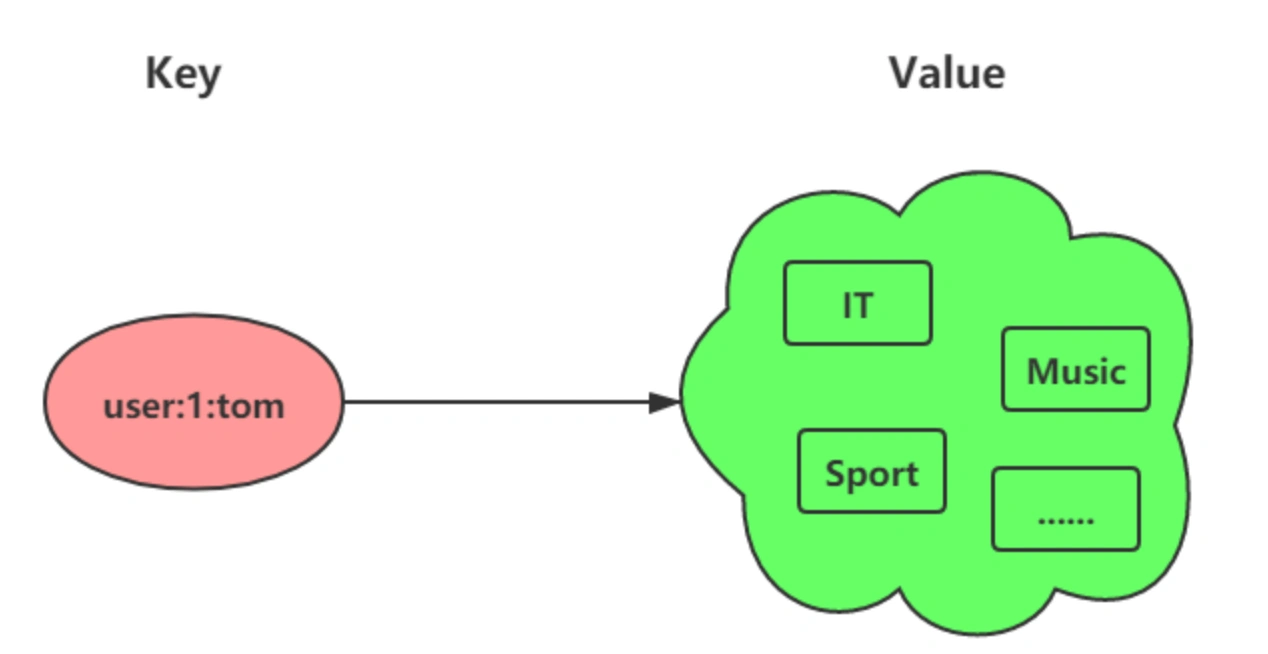
List 与 Set 的区别:
- List 可以存储重复元素,Set 不可以
- List 按照元素添加的顺序存储元素,Set 存储元素是无序的
🎗️ 常用命令
- 🧩 常用操作
| |
- 🧩 运算操作
⚠ Set 的交并差集运算的复杂度较高,在数据量较大时,如果直接执行计算,会导致 Redis 实例阻塞。 在实际中,推荐获取数据后,在客户端去完成计算。
| |
🎡 实现方式
Set 类型的底层数据结构由 (1)哈希表 或 (2)整数集合实现。
整数集合
- 元素个数少于 512 个,底层采用整数集合作为数据结构
哈希表
- 不满足以上条件,使用哈希表作为底层数据结构
🧵 使用场景
Set 主要是无续,不可重复,可求交并差的特性。
- 📐 点赞
Set 类型可以保证用户只能点一个赞。
- key -> 文章 id
- value -> 用户 id
| |
- 📐 共同关注
Set 支持交集运算,可以用来计算共同关注的好友,公众号等。
| |
- 📐 抽奖活动
key->活动名,value->用户名,存储某活动中中奖的用户名 ,Set 类型因为有去重功能,可以保证同一个用户不会中奖两次。
| |
🦥 Zset
Zset(有序集合,从小到大) 相比于 Set 类型多了一个排序分值 socre。
对于有序集合 ZSet 来说,每个存储的元素由两个值组成,一个是有序集合的元素值,一个是排序值。
Zset 中元素不能重复,分数值可以重复,并且可以排序。
🎗️ 常用命令
- 🧩 常用操作
| |
🎡 实现方式
有序集合 Zset 底层使用 (1)压缩列表 或 (2)跳表 作为数据结构。
压缩列表:有序集合中元素小于 128 个,并且每个元素的值小于 64 字节时,使用压缩列表作为底层数据结构。
跳表:不满足上述条件,使用调表。
🧵 使用场景
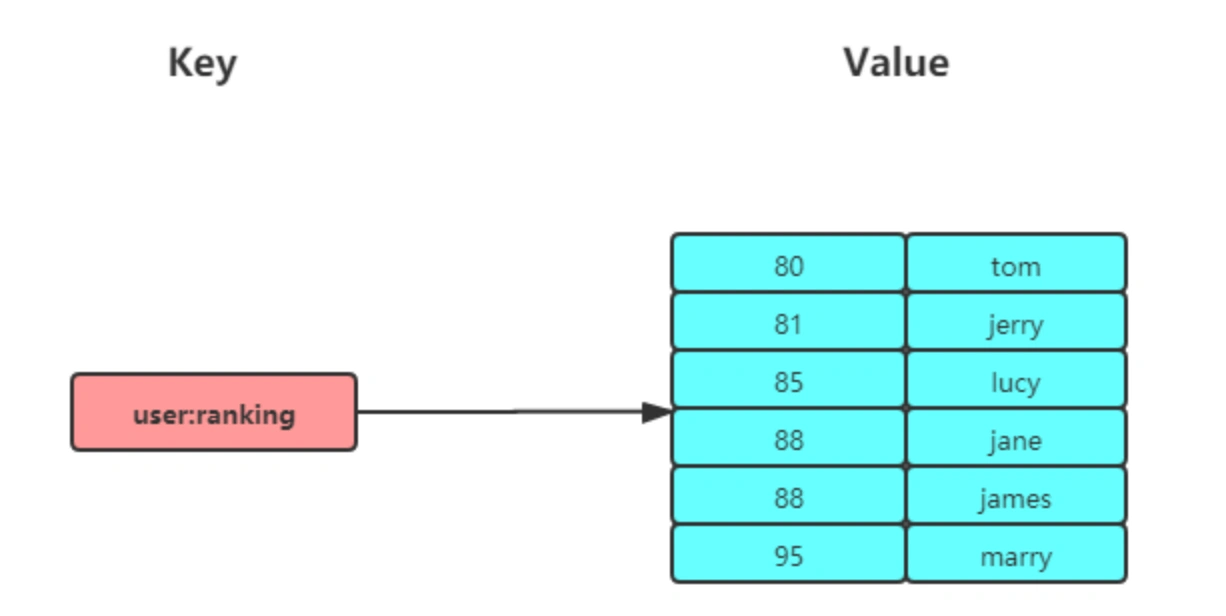
- 📐 排行榜
例如游戏积分排行榜,视频播放排名,电商系统中商品的销量排名。
key->排行榜的类型;member->需排行的内容(如文章id);score->点击数、点赞数等
| |
- 📐 延时队列
利用 score 存储延时执行的时间,使用 zrangebysocre 查询所有符合条件的待处理任务,再进行处理。