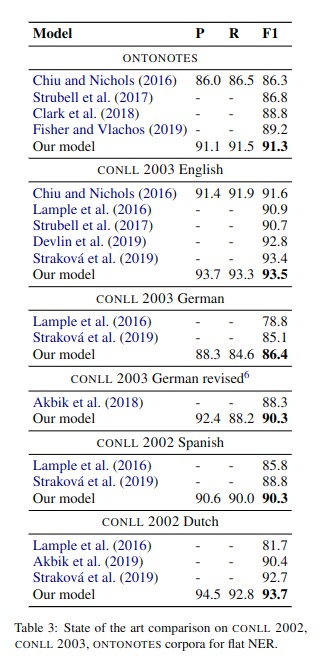
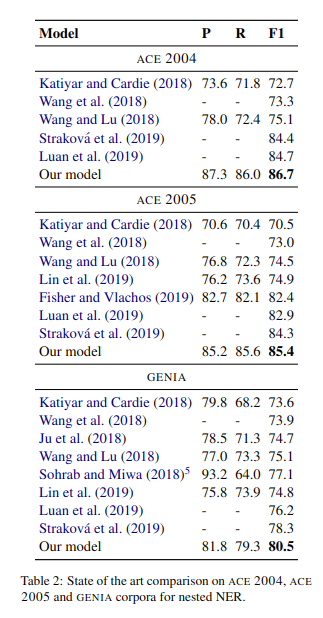
文中将每个 token 用 BERT 和 fastText 进行 embedding,拼接上用 CNN 编码的字符级别向量,送入一个双向 LSTM 编码上下文信息,获得每个词的表达。之后采用两个独立的 FFNN 来得到作为实体开始和结束的位置的表达。
最后用一个仿射模型得到一个 $l×l×c$ 的 tensor,其中 l 是句子长度,c 是实体类别数量加一(表示无实体)。运用该矩阵,文中对于嵌套和非嵌套采用了两种不同的策略,从而得到了实体的起止位置。
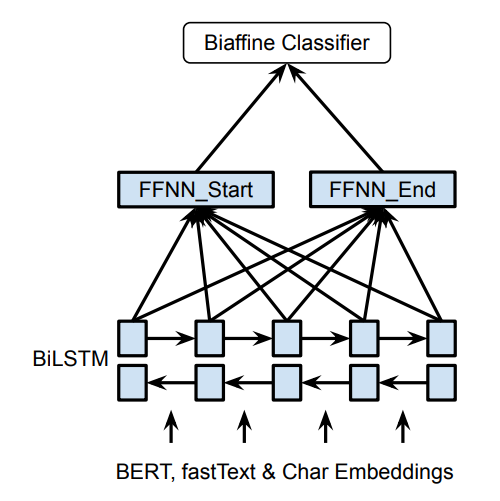
code: https://github.com/juntaoy/biaffine-ner