创建数据库
1
2
3
| create database test;
use test;
|
创建表
1
2
3
4
5
6
7
| create table mytable (
id int not null auto_increment,
col1 int not null default 1,
col2 varchar(45) null,
col3 date null,
primary key (`id`)
);
|
修改表
1
2
3
| alter table mytable add col char(20);
alter table mytable drop column col;
|
删除表
插入信息
1
| insert into mytable(col1, col2) values ("val1", "val2");
|
更新信息
1
| update mytable set col=val where id=1;
|
删除信息
1
| delete from mytable where id=1;
|
查询
distinct
去重
1
2
| select distinct col1, col2
from mytable;
|
limit
限制返回的行数
1
2
3
4
5
6
7
8
| -- 返回前5行
select * from mytable limit 5;
select * from mytable limit 0, 5;
-- 返回 3-5 行
-- offset:2, limit:3 跳过2行取3个结果
select * from mytable limit 2, 3;
select * from mytable limit 3 offset 2;
|
asc
升序(默认)
1
| select * from mytable order by col1 asc;
|
desc
降序
1
| select * from mytable order by col2 desc;
|
过滤
where
1
| select * from mytable where col is null;
|
通配符
1
2
3
4
5
6
| -- 不以 A B 开头的任意文本
select * from mytable where col like '[^AB]%';
-- 学号的最后一位不是2、3、5的学生信息
select * from 学生表 where 学号 like '%[^235]';
-- 查询学生表中姓 张、李、刘 的学生的情况。
select * from 学生表 where 姓名 like '[张李刘]%';
|
分组
GROUP BY
把具有相同的数据值的行,放在同一组中。
可以对同一分组数据,使用汇总函数进行处理,例如求分组数据的平均值。
指定的分组字段,处理能按字段进行分组,也会自动按该字段进行排序。
HAVING 过滤分组。
子查询
子查询只能返回一个字段的数据。可以将子查询的结果作为 where 语句的过滤条件。
1
2
3
4
5
6
| select * from mytable1
where col in (select col2 from mytable2)
select cust_name, (select count(*) from orders where orders.cust_id = customers.cust_id as corder_num)
from customers
order by cust_name;
|
连接
把两个或多个表的行结合起来
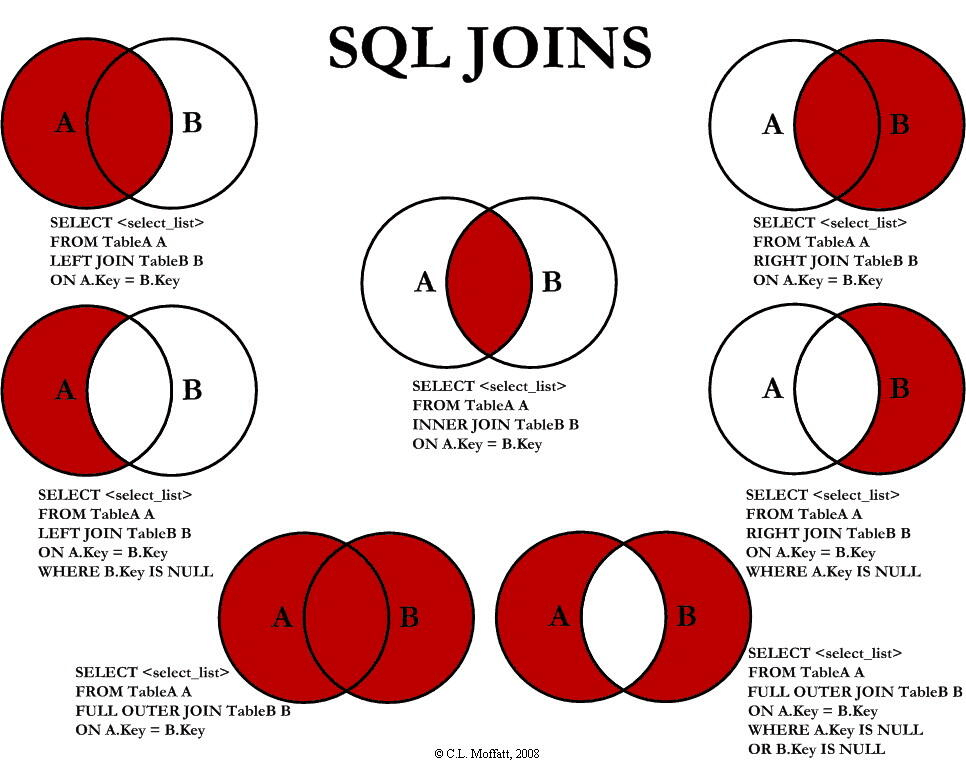
JOIN / INNER JOIN
表中存在至少一个匹配时返回行。
1
2
3
4
5
6
7
8
9
| select website.id, website.name, access_log.count, access_log.data
from website inner join access_log
on website.id = access_log.site_id;
--- inner join 和 join 是一样的
select website.id, website.name, access_log.count, access_log.data
from website join access_log
on website.id = access_log.site_id;
|
LEFT JOIN
从 左表 返回所有的行,即使右表中没有匹配。(没有匹配显示结果为 null)
1
2
3
4
5
6
| -- 返回所有的网站及他们的访问量(如果有的话)
-- 将 website 作为左表,access_log 作为右表
select website.name, access_log.count, access_log.date
from website left join access_log
on website.id = access_log.site_id
order by access_log.count desc;
|
RIGHT JOIN
从右表返回所有的行,即使坐标没有匹配。(左表没有匹配显示结果为 null)
1
2
3
4
5
6
| -- 返回所有网站的访问记录
-- 在左表中没有记录,也会显示 null
select website.name, access_log.count, access_log.date
from website right join access_log
on access_log.site_id = website.id
order by access_log.count desc;
|
FULL JOIN(不支持)
(MySQL 不支持,使用 union 拼接)
全连接。
只要左表,右表,其中一个表存在匹配,则返回行。
1
2
3
4
| select website.name, access_log.count, access_log.date
from website full join on website.is = access_log.site_id
on website.id = access_log.site_id
order by access_log.count desc;
|
自连接
1
2
3
4
5
6
7
8
9
10
11
| -- 找出与 jim 处在同一部门的所有员工的姓名
select name from employee
where department = (
select department from employee where name="jim"
);
--
select e1.name
from employee as e1 inner join employee as e2
on e1.department = e2.department and e2.name = "jim";
|
组合
union 组合两个查询。每个查询必须包含相同的列,表达式和聚集函数。
默认去除相同的行,如果需要保留相同的行,使用 union all。
1
2
3
| select col from mytable where col=1
union
select col from mytable where col=2;
|
函数
计算字段
- avg()
- round()
- round(x) 四舍五入;round(x, n) 保留 n 位小数
- count()
- max()
- min()
- sum()
文本处理
- left()
- right()
- lower()
- upper()
- ltrem()
- rtrem()
- length()
- soundex()
条件函数
expr 成立,返回结果 v1,否则返回 v2。
1
2
3
4
5
6
7
8
9
| -- SELECT IF(1 > 0,'正确','错误')
-- ->正确
-- --
-- 将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量
select if (age>=25, '25岁及以上', '25岁以下') as age_info, count(*)
from user_profile
group by age_info;
|
v1 的值不为 null,返回 v1,否则返回 v2。
1
2
3
4
5
6
7
8
9
| select ifnull(
(
select distinct salary
from Employee
order by salary desc
limit 1, 1
)
, null
) as SecondHighestSalary;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| -- 将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量
select
(
case
when age>=25 then "25岁及以上"
else "25岁以下"
end
) as age_info,
count(*) as number
from user_profile
group by age_info
;
-- 将用户划分为20岁以下,20-24岁,25岁及以上三个年龄段,分别查看不同年龄段用户的明细情况
select device_id, gender,
(
case
when age<20 then "20岁以下"
when age>=20 and age<=24 then "20-24岁"
when age>=25 then "25岁及以上"
else "其他"
end
) as age_cut
from user_profile
;
|
1
2
3
4
5
6
7
| update Salary
set sex=(
case set
when 'm' then 'f'
then 'f'
end
);
|
