
原因
随着互联网的发展和用户规模的迅速扩大,对系统的要求也越来越高。传统的 MySQL 单库单表架构的性能问题就暴露出来了。下面几个因素会影响数据库性能:
数据量
MySQL 单库数据量在 5000w 以内性能比较好,超过阈值后性能会随着数据量的增大而变弱。
MySQL 单表数据量是 500w-1000w 之间性能比较好,超过 1000w 性能也会下降。
磁盘
单个服务的磁盘空间是有限制的,如果并发压力下,所有的请求都访问同一个节点,肯定会对磁盘 IO 造成非常大的影响。
数据库连接
数据库连接是非常稀少的资源,如果一个库里既有用户、商品、订单相关的数据,当海量用户同时操作时,数据库连接就很可能成为瓶颈。
🐟 垂直拆分
当我们单个库太大时,如果表的数量太多,则应该将部分表进行迁移(如按业务区分),这就是所谓的垂直切分。
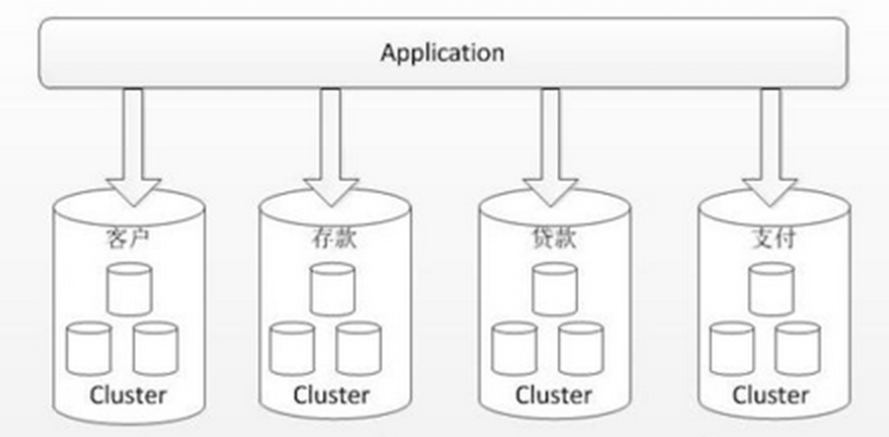
🐠 垂直分库
针对一个系统中的不同业务进行拆分,比如用户相关的一个库,商品相关的一个库,订单相关的一个库。
垂直分库后将用户、商品、订单放到多个不同的服务器上,不会面临单机资源问题。这种做法与“微服务治理”的做法相似,每个微服务使用单独的一个数据库。
🐡 垂直分表
基于列字段进行的,“大表拆小表”。
一般是表中的字段较多,将不常用的,数据较大,长度较长(比如text类型字段)的字段数据拆分到“扩展表“。
针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。
MySQL 底层是通过数据页存储的,一条记录占用空间过大会导致跨页,造成额外的性能开销(IO操作变多)。
数据也是以页为单位加载到内存中,页中存储的是行数据,大小固定,一行数据占用空间越小,页中存储的行数据也就越多。这样表中字段长度较短且访问频率较高,内存中能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
优缺点
优点:
- 解决业务系统层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,能提升一定的磁盘 IO,数据库连接数,单机硬件资源的瓶颈
缺点:
- 部分表无法 join
- 分布式事务处理复杂
- 还是存在单表数据量过大的问题
🐥 水平拆分
如果数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了。
🐤 水平库内分表
水平分表是基于全表的,将一个表中的数据拆分到多个表中,可以大大减少单表数据量,提升查询效率。
库内分表只是解决了单一表数据量过大的问题,没有将表分布到不同机器的库上,对于减轻 MySQL 数据库的压力来说,帮助不是很大,还是竞争同一个物理机的资源。
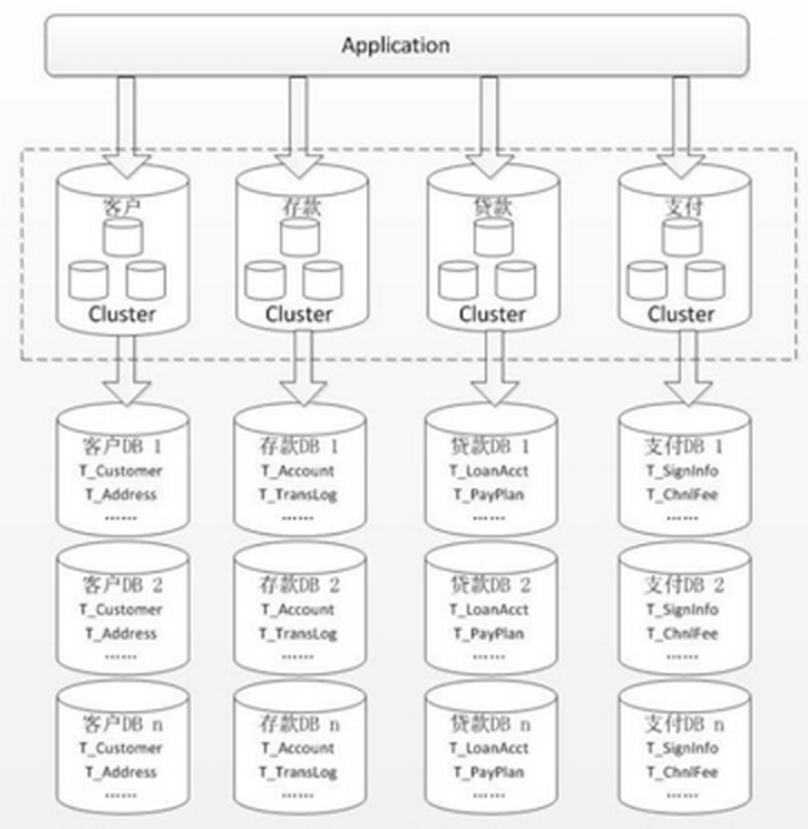
🐣 水平分库分表
将单张表的数据切分到多个服务器上去,每个服务器具有相同的库与表,但是表中的数据不同。
水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
优缺点
优点
- 不存在单库数据量过大,高并发的性能瓶颈,提升系统的稳定性和负载能力
- 应用端改造较小,不需要拆分业务模块
缺点
- 跨分片的事务一致性难以保证
- 跨库的 join 关联查询性能较差
- 数据多次扩展难度和维护量极大
常见分库分表的策略
🔢 根据数值范围划分
按照时间区间或 ID 区间进行区分。如:
- 🧩 按日期将不同月或不同日的分散到不同库中
- 🧩 根据 id 分,将 [0, 1000000] 分到第一个库,[1000001, 2000000] 分到第二个库
- 🧩 “冷热数据分离”,一些使用较少的历史数据迁移到其他库中,业务功能上只提供热点数据的查询
优点:
- 单表大小可控
- 天然便于水平扩展,扩容只需要添加节点,无需对其他分片数据进行迁移
- 在范围查找时,连续分片可以快速进行定位查询
缺点:
- 热点数据成为瓶颈。连续分片可能存在热点数据,如按时间分片时,有些最近时间的分片会被频繁读取,有些历史分片会很少查询
🧮 根据数值取模
一般采用 hash 取模的分片方式。
如根据用户 user_no 字段取余(根据数据库的数量取余),余数为 0 放到第一个库,余数为 1 放到第二个库,以此类推。(同一个用户会定位到相同的数据库)
优点:
- 数据分片相对来说比较均匀,不容易出现热点和并发访问的瓶颈。
缺点:
- 后期分片扩容时,需要迁移旧数据(使用一致性 hash 算法能较好避免)
- 容易遇到分片查询复杂问题,如通过 user_no 进行的分库分表,如果有多数查询条件中不包含 user_no 字段,就无法定位数据库,需要在所有的数据库发起查询
🌐 根据地理位置
根据地理位置,将相同地区的放到一张表中。如:华南区一个表,华北区一个表。
常见分库分表的问题
事务一致性问题
分布式事务
分布式事务能最大限度保证了数据库操作的原子性。
- 使用分布式事务中间件
- 使用 MySQL 自带的针对跨库的事务一致性方案(XA),性能要比单库的慢 10 倍左右。
- 在业务上,避免跨库操作(如将用户和商品放到同一个库中)
最终一致性
不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,可采用事务补偿的方式。
事务补偿是一种事后检查补救的措施,一些常见的实现方法有:对数据进行对账检查,基于日志进行对比,定期同标准数据来源进行同步等等。
跨节点关联查询 join 问题
多次查询进行数据组装
在系统层面,分两次查询,最后将获得到的数据进行字段拼装。
添加冗余字段
一种典型的反范式设计,利用空间换时间,为了性能而避免 join 查询。
但这种方法适用场景有限,适用于依赖字段比较少的情况。而冗余字段的数据一致性也较难保证,要结合实际业务场景进行考虑。
跨节点分页、排序、函数问题
先在不同的分片节点中将数据进行操作,在服务层进行汇总操作,最终返回给用户。
主键问题
UUID(不推荐)
使用 Redis 生成主键(incr 时自增的原子命令)
使用 Zookeeper 生成唯一 ID
雪花算法生成
百度 uidgenerator
美团 Leaf
滴滴 TinyID
数据迁移,扩容问题
如果采用数值范围分片,只需要添加节点就可以进行扩容了,不需要对分片数据迁移。
如果采用的是数值取模分片,针对数据量的递增,可能需要动态的增加表,因为reHash有可能导致数据迁移问题,则考虑后期的扩容问题就相对比较麻烦。
考虑切分的情况
能不切分就尽量不要切分
不到万不得已不用轻易使用分库分表这个大招,避免"过度设计"和"过早优化"。
数据量过大,正常运维影响业务访问
- 对数据库备份,如果单表太大,备份时需要大量的磁盘 IO 和网络 IO
- 对一个很大的表进行 DDL 修改时,MySQL会锁住全表,这个时间会很长,这段时间业务不能访问此表,影响很大
- 大表会经常访问与更新,就更有可能出现锁等待
随着业务发展,数据量快速增长
安全性和可用性
- 利用垂直切分,一个数据库出现问题,只会影响到部分业务,不会使所有的业务都瘫痪。
- 利用水平切分,当一个数据库出现问题时,不会影响到100%的用户,每个库只承担业务的一部分数据,这样整体的可用性就能提高。
常见分库分表中间件
sharding-jdbc
MyCat