事务
事务是一组逻辑上的数据库操作,这些操作要么全部成功,要么全部失败。
A原子性:事务是不可分割的最小操作单元,要么全部成功,要么全部失败。C一致性:事务完成时,必须使所有的数据都保持一致状态。I隔离性:数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。D持久性:事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
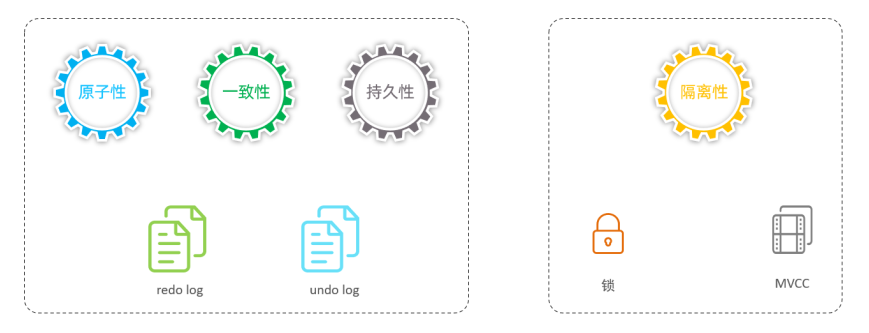
C(一致性)是目的,A(原子性)、I(隔离性)、D(持久性)是是为了保证一致性,数据库提供的手段。
🔃 redo log
重做日志,记录的是“某个数据页上做了什么修改”。(物理日志)
redo log 用来保障数据库的持久性。在一个事务中,执行增删改的操作时,InnoDB 引擎会先操作缓冲池 Buffer Pool 中的数据,如果缓冲区没有对应的数据,会通过后台线程将磁盘中的数据加载出来,存放在缓冲区中,再将缓冲池中的数据修改。
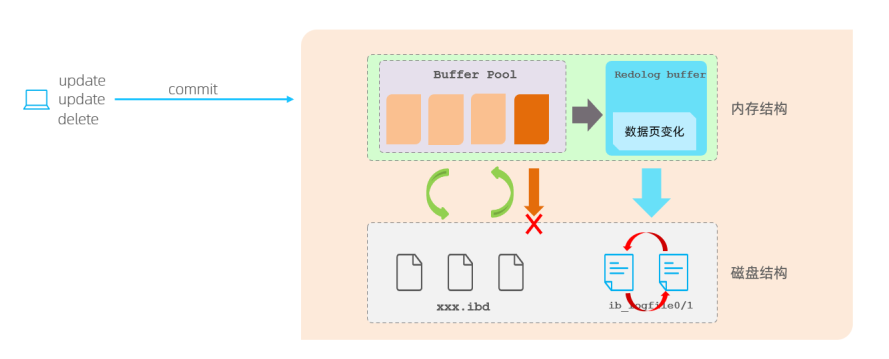
修改后的数据页我们称为脏页,缓冲区的脏页数据并不是实时刷新的,而是一段时间之后将缓冲区的数据刷新到磁盘中(随机磁盘 IO),从而保证缓冲区与磁盘的数据一致。
对缓冲区的数据进行增删改,会首先将操作的数据页的变化,记录在 redo log buffer 中。在事务提交时,将 redo log buffer 中的数据刷新到 redo log 磁盘文件中(顺序磁盘 IO)。
如果刷新缓冲区的脏页到磁盘时发生错误,或者发生了异常断电,就可以借助于 redo log 进行数据恢复,这样就保证了事务的持久性。
🔙 undo log
回滚日志。记录操作数据库的逆操作,用于进行回滚。
作用:
- 提供回滚操作(保障事务的原子性)
- 实现 MVCC 操作,提升数据库性能
undo log 是逻辑日志,在 InnoDB 存储引擎对记录进行修改时,会把回滚需要的信息全部记录到 undo 中,如果发生回滚,就会读取 undo log,然后执行与之相反的操作。
➕ 插入数据,记录这条数据的主键,回滚时根据主键把该条记录删除
➖ 删除数据,记录这条数据的所有内容,回滚时将这些内容组成的记录插入表中
🖋️ 更新数据,
- 更新了主键,会记录两条 undo log,一条删除的,一条更新的
- 没有更新主键,记录这条数据更新列的旧值,回滚时将数据更新为旧值
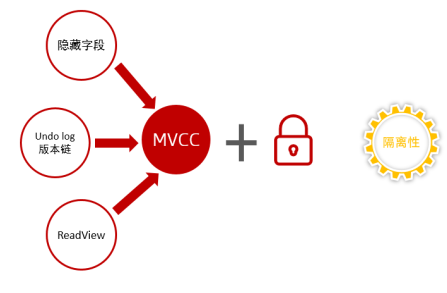
📔 MVCC
多版本并发控制,同一条记录在数据库中,可以存在多个版本。
依赖于:
- 行的隐式字段
- DB_TRX_ID 事务 id
- DB_ROLL_PTR 回滚指针(记录这条记录的上一个版本)
- undo log
- Read View
当前读
读取的是记录的最新版本。
update insert delete select ... for update select ... lock in share mode 都是进行当前读。
快照读
简单的不加锁 select 就是快照读。读取的是快照版本,通过 MVCC 进行并发控制。
🚀 关键特性
InnoDB 存储引擎的特性,可以带来更高的性能和可靠性。
🧮 插入缓冲 Insert Buffer
当插入一条数据的时候,在聚簇索引中,通常数据都是在叶子节点顺序存放的,只需要将插入的数据放到最后即可(主键顺序存放)。
通常我们都会在一张表上创建一些二级索引,而这些二级索引在数据插入时,需要维护索引是离散的,由于随机 IO 就会导致插入性能的下降。
为了解决以上问题,InnoDB 设计了 Insert Buffer。
二级索引的更新操作:
- 如果需要更新的索引页在 Buffer Pool 中,则直接插入;
- 如果不在,则插入 Insert Buffer,之后以一定的频率和情况在与二级索引合并
使用 Insert Buffer 需要满足两个条件:
- ⭐ 二级索引
- ⭐ 非唯一索引
如果二级索引是唯一的,在插入时,还需要去索引页查找改索引是否唯一,这样的离散读取两部分,会导致 Insert Buffer 失去意义。
后续的版本提供了升级版本 Change Buffer,对 Insert、Delete、Update 都进行缓冲。
🖋️ 两次写 Double Write
InnoDB 将脏页刷新到磁盘中时,突然发生宕机,只写入了一半,可能会发生数据丢失的问题。
InnDB 使用 Double Wirte 机制,给数据添加副本,防止数据丢失。
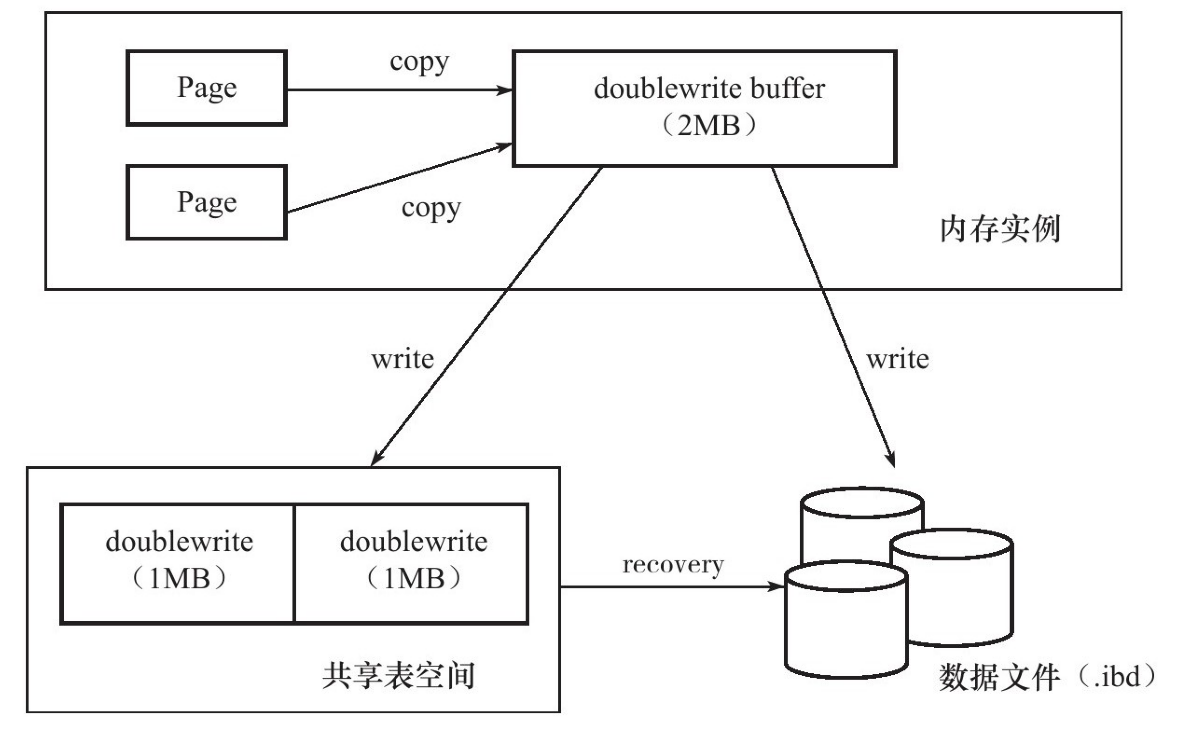
需要刷新的脏页会被复制到 Double Write Buffer 中,在需要刷盘时:
- 先分两次写入一份到共享表空间的 double wirte 物理磁盘上(顺序写入)
- 再将数据同步到磁盘中(随机 IO)
🗂️ 自适应哈希索引
InnoDB 存储引擎会自动根据访问的频率和模式给热点数据建立一个 Hash 索引,加快读请求。
只能为等值查询建立,范围查询不能建立。
📖 预读机制
InnoDB 会将查询页的邻近页一起读到 Buffer Pool 中。
通过改进的 LRU 链表(管理干净页 & 脏页的链表),解决了预读失效的问题。。