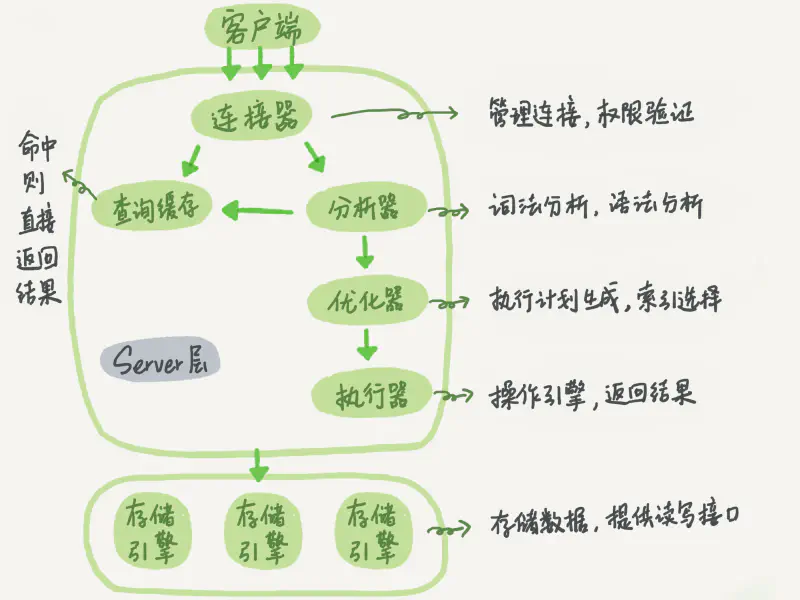
MySQL 可以分为:
(1)Server 层:负责建立连接,分析和执行SQL
(2)存储引擎层:负责数据的存储和提取
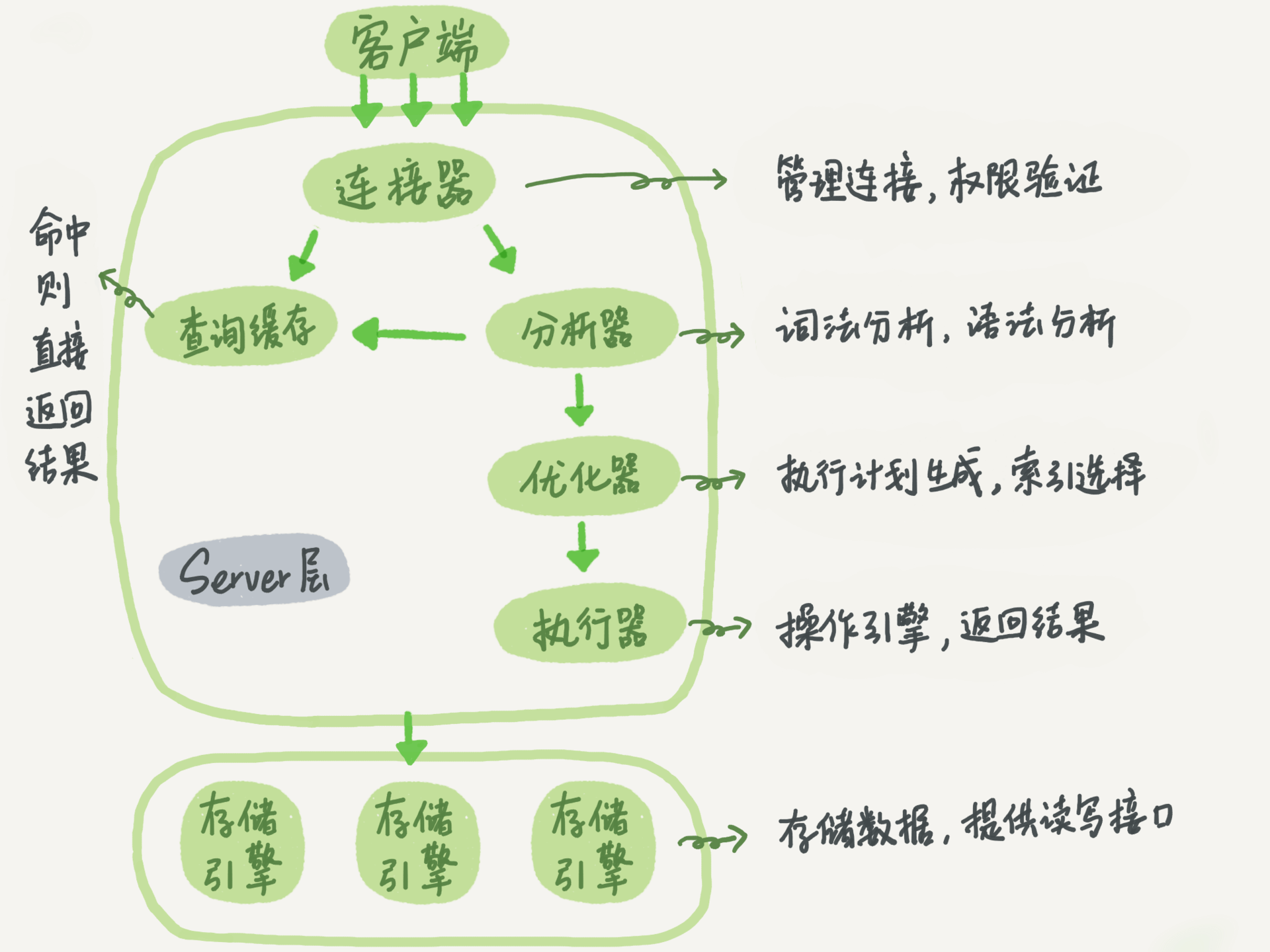
🛎️ Server 层
Server 层负责建立连接,分析和执行 SQL。主要包括:连接器、查询缓存、分析器、优化器和执行器等,包含 MySQL 大多数核心服务的公共功能。
🏒 连接器
当我们使用 MySQL 服务连接到数据库时,首先就是通过连接器。
连接器负责与客户端建立连接、获取权限、维持和管理连接。
通常使用以下命令连接数据库:
| |
🥍 查询缓存
🙅♂️ MySQL 8.0 已经移除了查询缓存。查询缓存的命中率非常低,除非都是静态表不会更新,只要有一个表更新了数据,这个表的查询缓存就会被清空,有时反而会影响数据库的效率。
客户端向 MySQL 发送 SQL 语句后,如果是 select 语句,会先去查询缓存中查找这条语句是否被缓存(key-value)。如果命中,会直接返回 value 给客户端。
🏏 分析器
词法分析
MySQL 会根据输入的字符串识别出关键字,如 SQL 类型、表名、字段名、where 条件等,构建出 SQL 语法树。
语法分析
根据词法分析的结果,语法解析器会根据语法规则,判断该 SQL 语句是否满足 SQL 语法。
🏑 优化器
优化器主要负责将 SQL 查询语句的执行方案确定下来。
比如在表中有多个索引的时候,优化器会基于查询成本的考虑,选择使用哪个索引。
比如判断走索引查询回表和全表扫描的代价,选择进行回表或全表扫描。
我们可以通过 explain 查看一个条查询语句的执行计划。
| |
🏓 执行器
通过优化器确定执行方案后,MySQL 开始真正执行语句了。
在执行过程中,执行器会与存储引擎进行交互,交互以记录(行)为单位。
对于要进行全表扫描的情况,执行器会调用 InnoDB 引擎接口的获取表的第一行,判断条件是否符合,符合就加入到结果集中。之后不断调用引擎接口重复这个过程,直到读取完表的最后一行。
对于要使用索引的情况,逻辑同样类似,会通过索引获取满足条件的第一行,根据情况是否要回表、覆盖索引或索引下推,再不断向后循环获取,直到不满足条件。
💽 存储引擎
存储引擎负责数据的存储和提取。
MySQL 存储引擎的架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。可以根据需要选择合适的存储引擎。通常我们会选择使用 InnoDB 存储引擎。
在 InnoDB 存储引擎中,如果查询的数据在 BufferPool 中,会直接返回;如果没有会将数据加载到内存中,在返回给客户端。