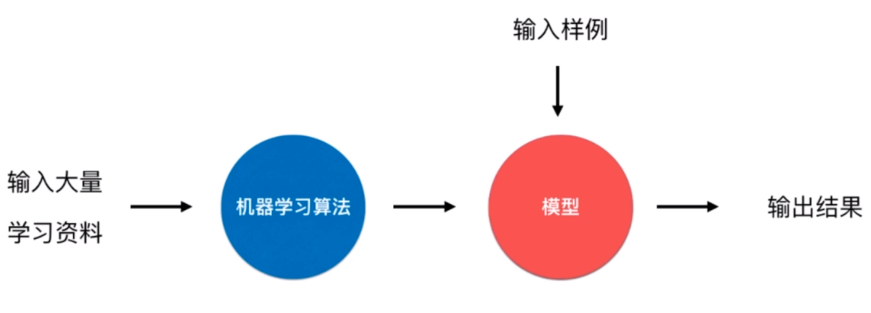
机器学习
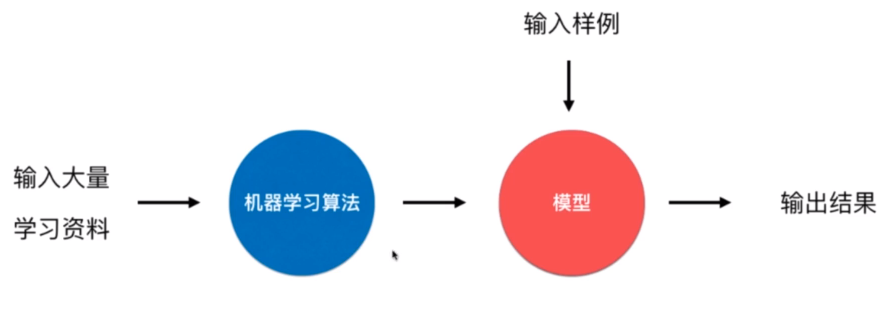
基本术语
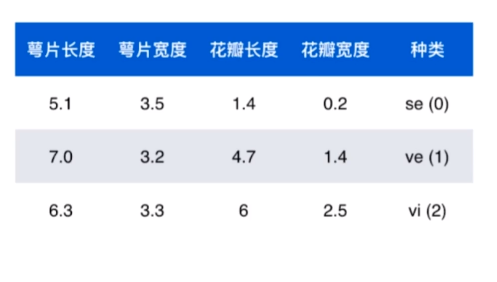
如图所示表格,是鸢尾花(lris)相关信息的数据,其中:
- 数据整体称为数据集(data set)
- 每一行数据称为一个样本(sample)
- 每一列(除表格最后一列)表达样本的一个特征(feature)
- 最后一列,成为标记(label)
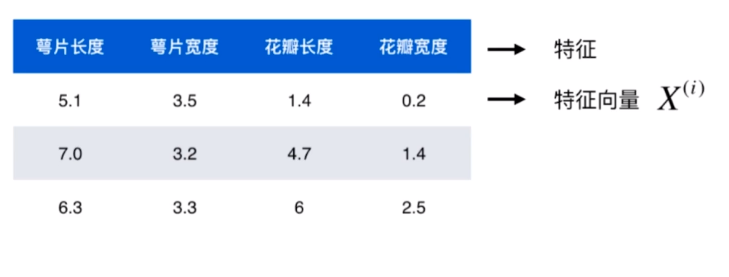
如图所示信息,其中 萼片长度、宽度,花瓣的长度、宽度称为 特征;每一行特征的值称为特征向量(数学上通常会将其表示为列向量)。
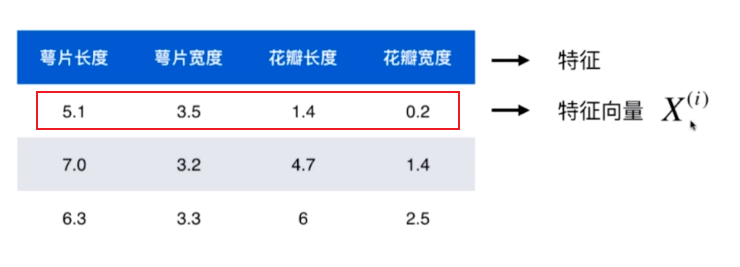
若将该图中的数据表示为矩阵的方式,结果如图:
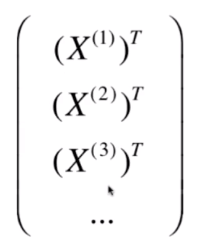
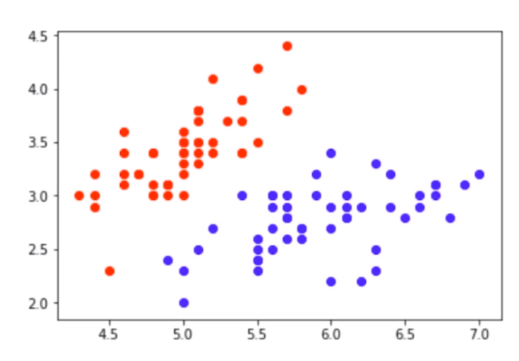
选择两种鸢尾花的特征为例,将其表示为如图的二维空间(多维特征将其表示为多维空间)。
我们将这样的空间称为 特征空间(feature space)。
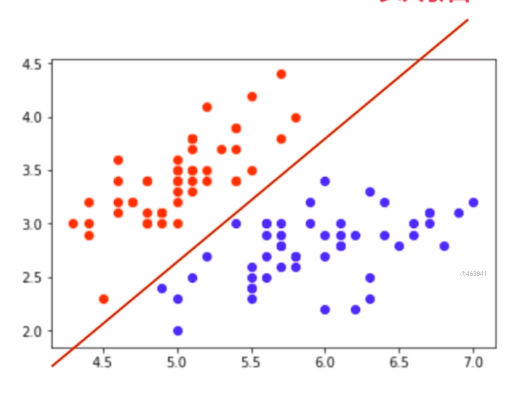
分类任务本质就是在特征空间切分,如图所示,在特征空间中,将鸢尾花根据两种特征分为了两类。
机器学习的基本任务
机器学习的基本任务基本有两类,分别为:
- 分类
- 回归
分类任务
- 一些算法只支持完成二分类的任务
- 多分类的任务可以转换成二分类的任务
- 一些算法天然的支持多分类问题
二分类
二分类问题的常见实例:
- 判断邮件是垃圾邮件;不是垃圾邮件
- 判断发放给客户信用卡有风险;无风险
- 判断病患良性肿瘤;恶性肿瘤
- 判断某支股票涨;跌
多分类
多分类问题的常见实例:
- 数字识别
- 图像识别
- 判断发放给客户信用卡的风险评级
- 围棋游戏等
- 自动驾驶识别
多标签分类
如图所示,为多标签分类问题的常见实例:

回归任务
回归问题的结果与分类问题的结果不同,回归问题的结果是一个连续数字的值,而非一个类别。
常见的回归问题有:
- 房屋价格
- 市场分析
- 学术成绩
- 股票价格
在一些情况下,回归任务可以简化成分类任务。
机器学习算法分类
监督学习
监督学习 supervised learning 主要处理的是分类问题和回归问题。
监督学习的含义是给机器的训练数据中拥有“标记”或者“答案”。根据这些数据进行模型的训练。
- 如根据图片判断猫狗(图像已经拥有了标定信息)

- 如更具手写字体识别数字(给出结果标记)

银行已经积累了一定的客户信息和他们信用卡的信用情况
医院已经积累了一定的病人信息和他们最终确诊是否患病的情况。
常见的监督学习算法有:
- k近邻
- 线性回归和多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林
非监督学习
非监督学习 unsupervised learning 给机器的训练数据没有任何“标记”或者“答案”。
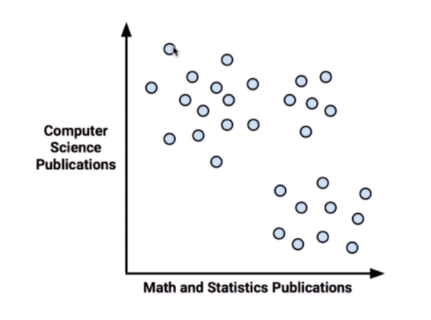
对没有“标记”的数据进行分类 – 聚类分析。
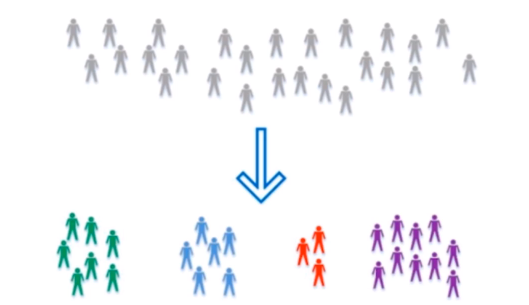
意义
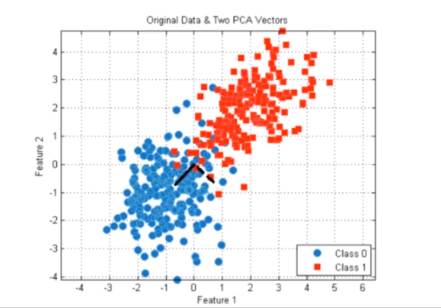
对数据进行降维处理
- 特征提取:行用卡的信用评级和人的胖瘦无关?
- 特征压缩:PCA
降维处理的意义:方便可视化
我们无法理解四维以上空间,所以可以将其降维到三维或者二维空间,方便理解。
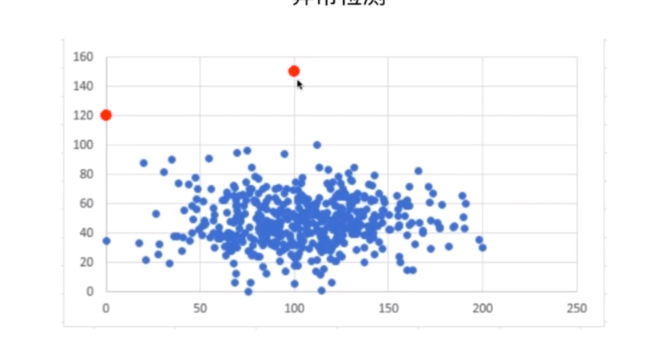
异常检测
半监督学习
semi-supervised learning
一部分数据有“标记”或者答案,另一部分数据没有
常见的场景:各种原因产生的标记缺失。
我们通常都先使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测。
增强学习
根据周围环境的情况,采取行动,根据采取行动的结果,学习行动方式。
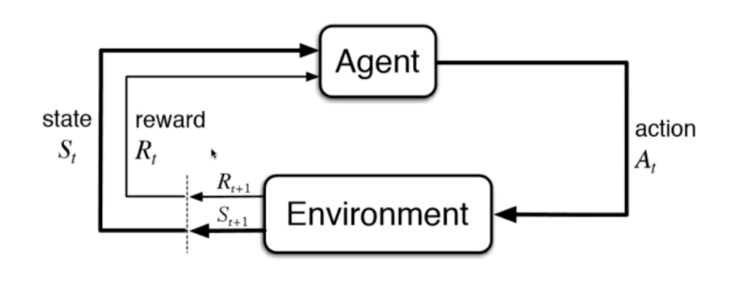
- 无人驾驶
- 机器人
在增强学习中,监督学习和半监督学习是基础。
机器学习的其他分类
在线学习和批量学习
在线学习
Online Learning
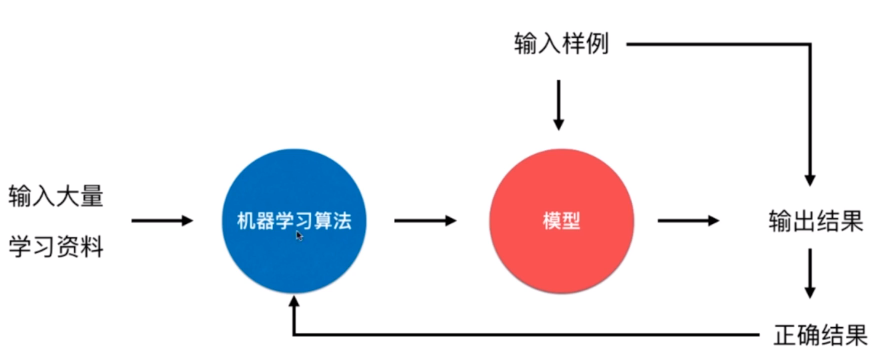
优点:及时反映新的环境变化
问题:新的数据可能带来不好的变化,错误的数据可能带来错误的结果
- 解决方案:需要加强对数据的监控
也适用于数据量巨大,完全无法批量学习的环境
批量学习(离线学习)
Batch Learning / Offline Learning
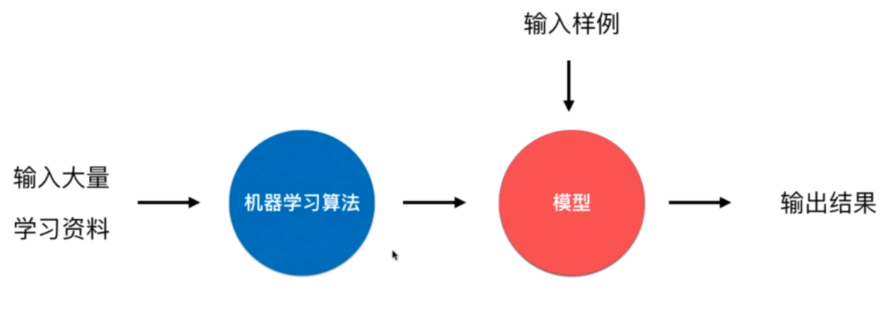
优点:简单
问题:要考虑如如何适应环境变化
- 解决方案:定时重新批量学习
缺点:每次重新批量学习,运行量巨大。在某些环境变化非常快的情况下,甚至是不可能的。
参数学习和非参数学习
参数学习
Parametric Learning
如图所示,为房屋面积与价格的关系曲线。
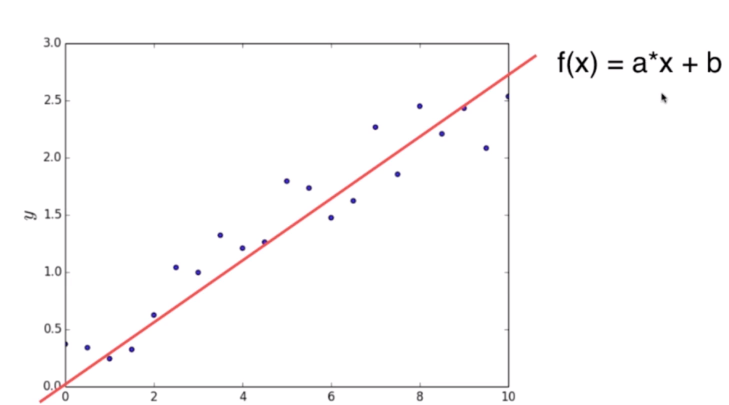
特点:一旦学习到了参数,就不需要原有的数据集。
非参数学习
Nonparametric Learning
不对模型进行过多假设
非参数不等于没有参数,而是对整个不进行建模,不学习一些参数