命令行工具
Kafka 提供了一些基于脚本的命名行工具 ${dir}/bin/xxx.sh,用于管理集群。这些管理通过 Java 类实现,通过脚本调用。
1
2
3
4
5
| # 启动 Zookeeper 服务(新版已内置)
bin/zookeeper-server-start.sh config/zeekeeper.properties
# 启动 Kafka 服务
bin/kafka-server-start.sh config/server.properties
|
🔍 更多 CLI 操作:🌐 https://www.conduktor.io/kafka/kafka-topics-cli-tutorial/
Topic 操作
Kafka 大部分命令行工具直接操作 Zookeeper 上的元数据,并不会直接连接到 Broker 上,需要确保所使用的工具版本与集群中的 Broker 版本相匹配。
🎗️
Kafka 2.2+ 使用 Kafka 的 hostname & port 进行操作 --bootstrap-server 127.0.0.1:9092
旧版本使用 Zookeeper 的 URL & port 进行操作 --zookeeper 127.0.0.1:2181
1
2
3
4
5
6
7
8
9
10
| # 创建主题
# 2.2 +
kafka-topics.sh --bootstrap-server localhost:9092 \
--create \
--topic first_topic \
--partitions 3 \ # 分区数量
--replication-factor 1 # 副本数量
# old
kafka-topics.sh --zookeeper localhost:2181 --topic first_topic --create --partitions 3 --replication-factor 1
|
1
2
3
4
5
| # 列出主题
# 2.2 +
kafka-topics.sh --bootstrap-server localhost:9092 --list
# 详细信息
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic first_topic
|
1
2
3
4
5
| # 修改主题
kafka-topics.sh --bootstrap-server localhost:9092 \
--alter \
--topic first_topic \
--partitions 5
|
生产 & 消费
🎗️ Producer
Kafka 2.5+ 使用 --bootstrap-server
旧版本 Kafka 使用 --broker-list
1
2
3
| # 生产
kafka-console-producer.sh --bootstrap-server localhost:9092 \
--topic first_topic
|
🎗️ Consumer
使用 --bootstrap-server,自 v0.10 开始 --zookeeper 已被废弃
1
2
| kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic first_topic
|
🤲 Producer
🐈 生产者
- 🧩
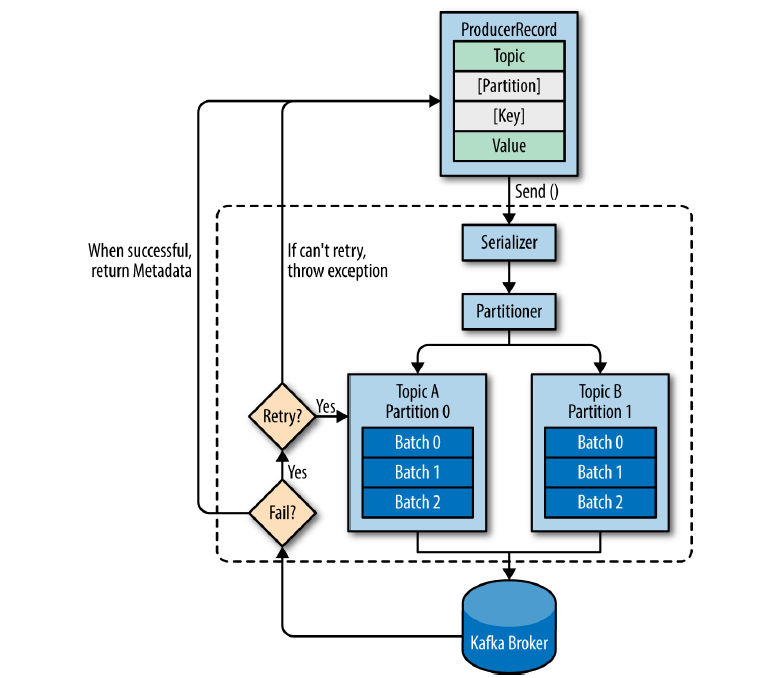
ProducerRecord 对象包含目标主题 Topic 和需要发送的内容 Value,可以可以指定分区 Partition 和键值 Key(消息的附加信息,可以用来决定消息被写入哪个分区,相同 Key 的消息会写入同一个分区) - 🧩 发送消息时,生产者需要将
ProducerRecord 对象序列化为字节数组,在网络上传输 - 🧩 数据被传送给分区器
Partitioner,如果指定了分区,会直接返回;没有指定,根据 Key 选择一个分区;没有指定 Key,会根据 Value 进行散列,根据散列值把消息映射到相应的分区 - 🧩 这条记录选好分区后,会被添加到一个记录批次中,这个批次的所有消息会被发送到相同的主题和分区上(批处理),独立的
Processer 线程会负责把这些数据发送到对应的 broker 上 - 🧩 Broker 收到消息时会返回一个响应
- 消息成功写入 Kafka,返回一个
RecordMetaData 对象,包含主题和分区的信息 - 写入失败,会返回一个错误,生产者收到错误之后会尝试重新发送,多次失败直接返回错误信息
重要配置
acks
指定了必须要有多少个分区副本收到消息,生产者才会任务消息写入时成功的
acks=0 不会等待任务来自服务器的响应。达到最高的吞吐量,无法得知消息状态。acks=1 只要 Partition Leader 收到响应。消息可能会丢失,Leader宕机后,一个未同步的Fllower成为新的Leader。acks=all 消息要全部同步到所有的 Leader&Fllower。
retries
生产者可以重发消息的次数
max.in.flight.requests.per.connection
生产者在收到服务器响应前可以发送多少个消息。
Kafka 可以保证同一个分区里的消息是有序的,max.in.flight.requests.per.connection=1,即使发送了重试,消息依旧有序,但是会严重影响生产者的吞吐量。
🐈⬛ 同步发送
1
| public Future<RecordMetadata> send(ProducerRecord<K, V> record) { }
|
使用 send() 方法发送消息,会返回一个 Future 对象,调用 get() 方法进行等待,就可以知道消息是否发送成功。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| // 相关配置
String bootstrapServers = "127.0.0.1:9092";
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // 序列化方式
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 创建 Producer
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
// 创建消息
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("demo_topic", "hello world!");
// 发送消息
try {
producer.send(record).get(); // get() 同步
} catch (Exception e) { // 发生了无法解决的错误 或 重试超过最大次数
e.printStackTrace();
}
|
🐅 异步发送
1
| public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) { }
|
调用 send() 方法,并指定一个回调函数,服务器在返回响应时调用该函数。
1
2
3
4
5
6
7
8
9
| producer.send(producerRecord, new Callback() {
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
// 发送失败
// ...
// 对应的业务处理逻辑
}
}
});
|
🐆 序列化器
常见的序列化&反序列化器有 Avro、Thrift、Protobuf 等。
Apache Avro 是一种与编程语言无关的序列化格式。
Avro 通过与语言无关的 schema 来定义,使用 JSON 来描述,数据会被序列化为二进制文件或 JSON 文件。
满足 Avro 兼容原则下,写入的消息改动 schema 写入了新的数据,负责读消息的应用程序可以继续处理而无需做任何更改。
🐕 分区
ProducerRecord 对象可以包含 topic、partition、key、value 等,通常我们会指定 key,作为附加消息,决定消息该被写入哪个分区,拥有相同 key 的消息会被写入同一个分区。
1
2
3
4
5
6
7
| // topic: CustomerCountry
// key: Laboratory Equipment
// value: USA
ProducerRecord<String, String> record = new ProducerRecord<>("CustomerConuntry", "Laboratory Equipment", "USA");
// 创建 key->null 的消息
ProducerRecord<String, String> record = new ProducerRecord<>("CustomerCountry", "USA");
|
当 key 为 null 时,Kafka 会对键进行散列(Kafka 自己的散列算法),然后根据散列值映射到特殊的分区。
自定义分区策略
通过实现 interface Partitioner 实现自定义分区策略,主要包含:
void configure(Map<String, ?> configs)void partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster)void close()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class BananaPartitioner implements Partitioner {
void configure(Map<String, ?> configs) {}
// 自定义分区策略
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partition.size();
if ((keyBytes == null) || (!(key instanceOf String))) {
throw new InvalidRecordException("We expect all messages to have customer name as key");
}
if (((String) key).equals("Banana")) { // Banana 总是被分配到最后一个分区
return numPartitions;
}
// 其它记录被散列到其他分区
return ((Math.abs(Utils.murmur2(keyBytes))) % (numPartitions - 1));
}
void close() { }
}
|
👌 Consumer
🦜 消费者组
🦚 消息轮询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| // 配置
String bootstrapServers = "127.0.0.1:9092";
String groupId = "demo_groupId";
String topic = "demo_topic";
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 订阅主题
consumer.subscribe(Arrays.asList(topic));
// 轮询
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); // 100 -> 超时时间
for (ConsumerRecord<String, String> record : records){
// 业务处理
log.info("Key: " + record.key() + ", Value: " + record.value());
log.info("Partition: " + record.partition() + ", Offset:" + record.offset());
}
}
|
消息轮询是消费者 API 的核心,一旦消费者订阅的主题,轮询会处理所有的细节。
poll() 会负责查找 GroupCordinator,加入群组,接受分配的分区,发送心跳和获取数据。如果发生了再均衡,也是这个轮询期间进行的。
⚠️ 消费者组中的一个消费者只能运行在一个线程中。如果需要多个线程处理一个 Patition 中的消息,可以将这个消费者获取的一批数据,可以使用 ExecutorService 启动多个线程处理。
🦉 偏移量
Kafka 使用偏移量 offset 追踪消息在分区中的位置。
Consumer 向一个特殊的主题 _consumer_offset 发送消息,更新分区当前的位置。
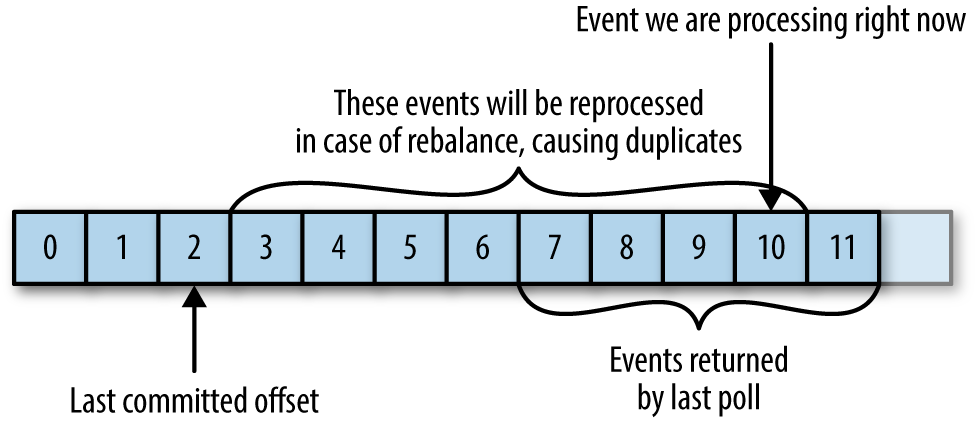
- 如果提交的 offset「小于」客户端处理的最后一个消息偏移量,那么「两个偏移量之间的消息会被重复处理」
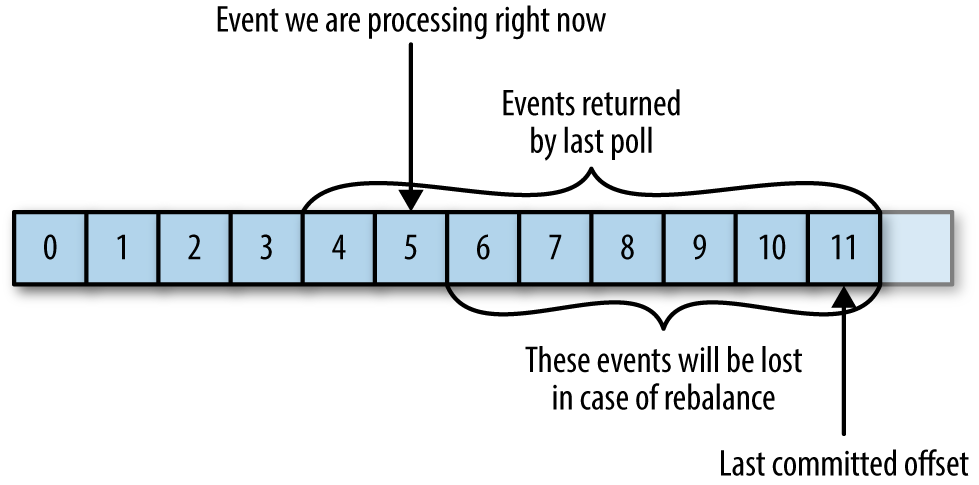
- 如果提交的 offset「大于」客户端处理的最后一个消息偏移量,那么「两个偏移量之间的消息会丢失」
自动提交
如果 enable.auto.commit = true,消费者会自动把从 poll() 方法接收到的最大偏移量提交上去。提交的时间间隔由 auto.commit.interval.ms 控制,默认为 5s。
自动提交发生在每次轮询时,如果没有提交偏移量,会把上一次调用返回的偏移量提交上去,「不能保证这些消息已经被业务处理了」。
⚠️ 如果设置默认提交时间为 5s,在提交后 3s 发生了再均衡,之后的消费者会再次获取到 3s 前提交的偏移量,这些消息会被重复处理,「无法避免这种情况」,只能缩小提交的时间间隔更频繁地提交 offset,「Kafka 也没有为自动提交预留避免重复处理消息的方法」。
适合于不重要的消息场景,如日志采集。
同步提交
设置 auto.commit.offset = false,可以让应用程序决定在什么时候提交偏移量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
// ...
// 处理业务
// ...
try {
consumer.commitSync(); // 手动提交
} catch (CommitFailedException e) {
log.error("commit failed", e);
}
}
}
|
只要没有发生不可恢复的错误,commitSync() 方法会「一直尝试直到提交成功为止」。如果提交失败,则抛出异常。
异步提交
使用异步提交 API,只管发送提交请求,无需等待 Broker 的响应。
1
| consumer.commitAsync();
|
同步提交 commitSync() 会一直重试,但是异步提交 commitAsync()「不会重试」。不进行重试,是因为在收到服务器响应的时候,可能有一个更大的 offset 已经提交成功。
异步提交同样支持回调。
1
2
3
4
5
6
7
8
| consumer.commitAsync(new OffsetCommitCallback()) {
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e) {
if (e != null) {
// 异步提交失败
// ... 业务处理 / 重试
}
}
}
|
异步提交重试,可以使用一个单调递增的序列号维护异步提交的顺序。在进行重试前,先检查回调序列号与维护的序列号的大小,如果回调序列号较大,说明有一个新的提交已经发送,不应该重试。
组合提交
一般情况下,偶尔的提交失败不进行重试没有太大问题,只要后续有更大的 offset 成功提交,就不会有问题。
所以,在消费者关闭前,可以组合使用两种提交方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| try {
while (true) {
// ...
// 消费消息业务
// ...
comsumer.commitAsync(); // 异步提交
}
} catch (Exception e) {
log.error("Unexpected error", e);
} finally {
try {
consumer.commitSync(); // 同步,会不断重试
} finally {
consumer.close();
}
}
|
提交特定偏移量
每次消费者 poll() 的都是一批数据,commitSync() / commitAsync() 每次提交都是这个批次最后的 offset,如果想要在批次中间提交偏移量,可以传入「希望提交的分区和偏移量的 map」。
但是,消费者可能不知读取一个分区,这样做需要「跟踪所有分区的偏移量」,通常会使代码变得很复杂。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| private Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
int count = 0;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100); // 假设每个批次 10000 条数据
for (ConsumerRecord<String, String> record : records) {
// 业务处理
// ...
currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, "no metadata"));
if (count % 1000 == 0) { // 在每个批次中,没处理 1000 条数据提交一次 offset
consumer.commitAsync(currentOffsets, null);
}
count++;
}
}
|
🦩 特定offset开始处理
如果想要从分区的起始/末尾位置读取消息,可以直接使用 seekToBeginning(Collection<TopicPartition> tp) 和 seekToEnd(Collection<TopicPartition>)
有时,在业务上需要从特定的 offset 开始读取消息,可以使用 seek() 进行查找。
1
2
3
4
5
| // class KafkaConsumer
void seek(TopicPartition partition, long offset);
void seek(TopicPartition partition, OffsetAndMetadata offsetAndMetadata);
|
比如在一些业务中,对所有的操作都要进行处理,不能丢失消息,处理消失后要将结果记录到数据库、NoSQL 存储引擎等地方,需要将「保存记录」「偏移量」放在一个原子操作里完成,要么全部成功,要么全部失败。可以将记录和偏移量都保存在数据库中,用一个事务操作,保证原子性。当消费者分配新分区时,就可以使用 seek() 查找保存在数据库中的指定offet了,不会丢失数据和重复处理。
🖇️ Connect
💦 Stream