
🤿 深入 Kafa
🛩️ 集群与控制器
Kafka 使用 Zookeeper 来维护集群成员的信息,每个 Broker 都有一个唯一标识符(可以在配置中指定或随机生成),在 Broker 启动时,通过创建临时节点将自己的 ID 注册到 Zookeeper。
控制器本身就是一个 Broker,复制分区领导的选举工作。集群的第一个启动 Broker 通过在 Zookeeper 中创建一个 /controller 临时节点让自己成为控制器,其他 Broker 启动时再尝试创建,会收到节点已经存在异常,会在控制器节点上创建 Zookeeper watch 对象,接受节点变更通知,确保集群中只会有一个控制器存在。
✈️ 复制
复制功能可以让 Kafka 在个别节点失效时,仍然保证 Kafka 的可用性和持久性。
Kafka 使用 Topic 组织数据;每个 Topic 被分为若干个 Partition;每个 Partition 有多个副本,被保存在 Broker 上。副本有两种类型:
首领副本
leader每个 Partition 都有一个首领副本。为了保证一致性,首领副本复制所有的 生产 & 消费请求。
同步副本
follower同步副本不处理任何请求,唯一的任务就是从 Leader 复制消息,保持与 leader 一致的状态。follower 向 leader 发送获取数据的请求(与消费者获取数据的请求相同),leader 将消息响应发送给 follower,包含指定偏移量的消息(有序)。
🛫 处理请求
Broker 处理客户端的请求并做出响应,会按照请求达到的顺序进行处理,这种「顺序性保证让 Kafka 具备了消息队列的特性。」
Broker 会在它所监听的每一个端口上运行一个 Acceptor 线程,监听到达的连接(IO多路复用);当请求达到时,会利用 n 个 Processor 线程进行处理,复制从客户端获取请求消息,并放入请求队列;放入请求队列的消息,会有 m 个 Handler 线程进行处理。
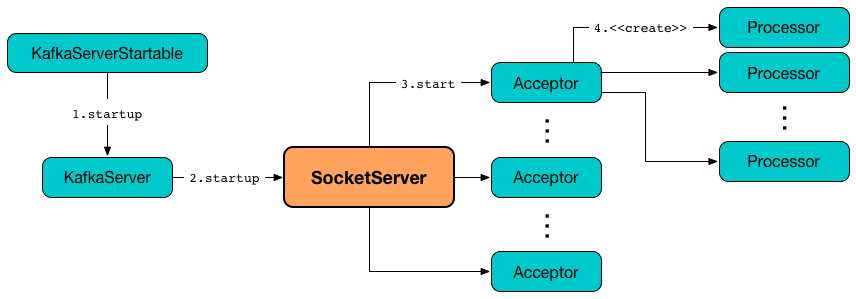
元数据请求
客户端使用「元数据请求」,获取所有主题列表(分区、首领、副本等所有信息),并将这些信息缓存起来,以此知道向哪里发送请求。
元数据请求会定时/遇到错误时,定时刷新。
生产请求
Kafka 使用
acks = 0/1/all客户端配置,指定了需要多少个 Broker 确认才可以认为一个消息是写入成功的。消息被 Broker 写入本地磁盘。在 Linux 系统上,消息会被写到文件系统缓存 Page Cache 里,并不保证什么是否会被刷新到磁盘上。Kafka 依赖复制功能保障消息的持久性。
消费请求
Consumer 向 Broker 发送请求,从主题分区里获取特定偏移量的消息,类似于说:“请把主题 Test 分区 0 偏移量从 53 开始的消息发给我”
其他请求
在旧版本的 Kafka 中,消费者使用 Zookeeper 来跟踪偏移量,在消费者启动的时候,通过检查保持在 Zookeeper 上的偏移量知道从哪里开始处理消息。
在新版本中,偏移量 offset 保存在特定版本的 Kafka 主题
__consumer_offset上。
💺 物理存储
Kafka 的基本存储单元是分区 Partition。
文件管理
保留数据是 Kafka 的一个基本特性,Kafka 不会一直保留数据,也不会等到所有的数据都消费完才删除。Kafka 可以为每个主题配置数据的保留期限,规定数据在删除之前可以保留多长时间,或者清理数据之前可以保留的数据大小。
Kafka 保存的数据通常都是很庞大的,在一个大文件中查找和删除消失是很费时的,也很容易出错,所以会把每个分区分成若干个「片段」
Partition -> Segment。 在 Broker 向 Partition 写入数据时,如果达到上限,就关闭当前文件,并打开一个新文件。当前正在写入数据的片段叫做活跃片段,「活跃片段永远不会被删除」。(即使活跃片段中的消息超过了保留时间,片段在被关闭之前无法被删除)
文件格式
Kafka 把消息和偏移量保存在文件里,保存在磁盘上的数据格式与从生产者发送来或发送给消费者的数据格式是一样的,Kafka 不会进行处理。
生产者发送的是被压缩过的消息,同一个批次的消息会被压缩在一起,发送给 Broker,然后 Broker 再发送给消费者。
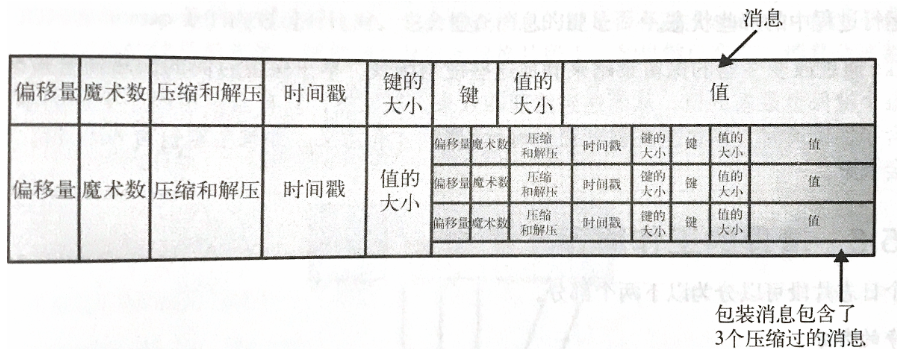
索引
Kafka 给每个分区都维护了一个稀疏的哈希索引,把偏移量映射到片段文件和偏移量在文件里的位置。
索引和 Partition 一样被分为片段,所以在删除消息时,也会删除相应的索引。
Kafka 不会维护索引的校验和,索引出现损坏,或删除了索引(完全安全),Kafka 都会自动重新生成索引。
👌 可靠数据传递
Kafka 的可靠性并不是单方面的事情,应该从整个系统层面来考虑可靠性的问题,如应用架构、生产者消费者的配置、主题配置、Broker 配置。
系统的可靠性需要在许多方面做出权衡,如复杂性、可用性、磁盘空间使用等。
🚗 可靠性保证
关系型数据库使用 ACID 机制来保障数据的可靠性。一个系统的保证机制对于构建可靠的应用程序来说至关重要。
Kafka 可以再以下方面作出保证:
🛸 Kafka 可以保证 分区 Partition 消息的顺序。
使用同一个生产者往同一个分区写入消息。
🛸 只有当消息被写入分区的所有同步副本时(不一定要写入磁盘),消息才被认为是“已提交“的。
生产者可以选择接收不同类型的确认(acks)。
🛸 只要还有一个副本是活跃的,已提交的消息就不会丢失。
🛸 消费者只能读取到已提交的消息。
我们可以通过 Kafka 的相关配置参数,对所需要的可靠性做出「权衡」:消息的「可靠性、一致性」的重要程度与「可用性、高吞吐量、低延迟、硬件成本」的重要性之间的权衡。
🚓 复制的可靠
Kafka 的复制机制和分区副本架构是 Kafka 可靠性保证的核心。
把消息写入多个副本可以使 Kafka 在发生崩溃时,保证消息的「持久性」。
Kafka 的主题 Topic 被分为多个分区 Partition,分区是最基本的数据块。分区可以有多个副本,包含一个首领 leader 和多个同步副本 follower,leader 负责读&写事件,其他副本只需要与首领保持同步,并及时复制最新的事件。
🚕 Broker 的可靠
Broker 有 3 个配置参数会影响 Kafka 存储消息的可靠性。(可以应用在 broker 级别,控制所有主题的行为;也可以单独应用在 Topic 级别,控制单个主题)
✒️ 复制系数
- Broker 级别:
default.replication.factor - Topic 级别:
replication.factor
复制系数表示该 Topic 的 Partition 会被几个不同的 Broker 复制。
如果复制系数为 N,当有 N-1 个 Broker 失效时,仍然可以从 Topic 读取或写入数据。
更高的复制系数能够带来更高的可用性、可靠性和更少的故障,但会占用成倍的存储空间,需要在可用性和存储硬件间做出平衡。
- Broker 级别:
✒️ 不完全的首领选举
- 只有 Broker 级别,默认为 true :
unclean.leader.election = true
在选举过程中没有丢失数据,这个选举就是”完全“的(提交的数据同时存在于所有同步副本上)。
如果设置为 true,允许不同步的副本成为首领,需要承担数据不一致或丢失数据的风险。
- 只有 Broker 级别,默认为 true :
✒️ 最少的同步副本
- Broker / Topic 级别:
min.insync.replicas
消息只有在被写入到所有同步副本之后才被认为是已提交的。
当不满足最少同步副本时,会停止接受生产者请求,变成只读状态。
- Broker / Topic 级别:
🛺 生产者的可靠
🧲 发送确认
三种确认模式:
acks: 指定了必须要有多少个分区副本收到消息,生产者才会任务消息写入时成功的acks=0不会等待任务来自服务器的响应。达到最高的吞吐量,无法得知消息状态。acks=1只要 Partition Leader 收到响应。消息可能会丢失,Leader宕机后,一个未同步的Fllower成为新的Leader。acks=all消息要全部同步到所有的 Leader&Fllower。
🧲 配置重试参数
生产者向 Broker 发送消失时,会返回一个成功/错误响应码。如果 Broker 返回的错误可以通过「重试」来解决,生产者会自动处理这些错误。
错误响应码可以分为两种:(1)重试之后可以解决的,可重试错误
LEADER_NOT_AVAILABLE(2)无法通过重试解决的,不可重试错误INVALID_CONFIG如果想抓住异常并多重试几次,可以将重试次数设置多一点,让生产者重试
如果想丢弃数据,重试参数毫无意义
如果想保存消息到某个地方,后续进行处理,可以停止重试
⚠️ 重试会带来消息重复的风险,可以在应用中向消息中加入唯一标识符,用于检测重复消息(新版 Kafka 能够自动处理),消费者在读取时进行清理;在业务上也可以实现幂等,即使出现重复消息,对结果的处理也不会造成负面影响。
🧲 额外的错误处理
错误处理器的代码逻辑与具体的应用程序及其目标有关,根据具体的架构决定。(丢弃?记录错误?保存到磁盘?回调另一个应用?)
如果错误处理只是为了重试发送消息,最好还是使用生产者内置的重试机制。
🚙 消费者的可靠
只有被写入所有同步副本的数据,对消费者才是可用的,消费者得到的消息已经具备了一致性。
消费者需要做的是跟踪哪些消息已经读取过,哪些是还没有读取过的,是在读取消失时不丢失消息的关键。
📐 提交频率(是性能和重复消息之间的权衡)
可以在轮询后维护状态,也可以在一个循环里多次提交偏移量,完全取决于性能和重复处理消息之间做出权衡。
📐 消费者需要重试
在进行轮询后,有些消息不会被完全处理,需要稍后重试。如记录 #31 处理成,记录 #30 处理失败。提交偏移量时需要进行处理(#31?/ #30)
遇到可重试错误时,提交最后一个处理成功的偏移量,将没有处理好的消息保存到缓冲区中,调用消费者的 pause() 确保其他轮询不会获取数据(停止接收消息防止缓冲区溢出),在保存轮询(保持心跳)的情况下尝试重新处理。如果重试成功或重试次数达到上限并决定放弃,将结果记录下来,使用 resume() 继续从轮询中获取数据。
遇到可重试错误,把错误写入到一个单独的主题,继续处理业务。使用专门的消费者从这个单独的主题上读取消息进行重试。
📐 长时间处理消息
有时处理数据需要很长的时间。「即使不想获取更多的数据,也要保持轮询,这样客户端才能向 Broker 发送心跳。」