
Apache Kafka is an open-source distributed event streaming platform.
Kafka 是一个开源的分布式事件流平台。
📑 基本概念
Productor & Consumer
把消息放到队列里面的叫「生产者」;从队列中消费消息的叫「消费者」。

Topic
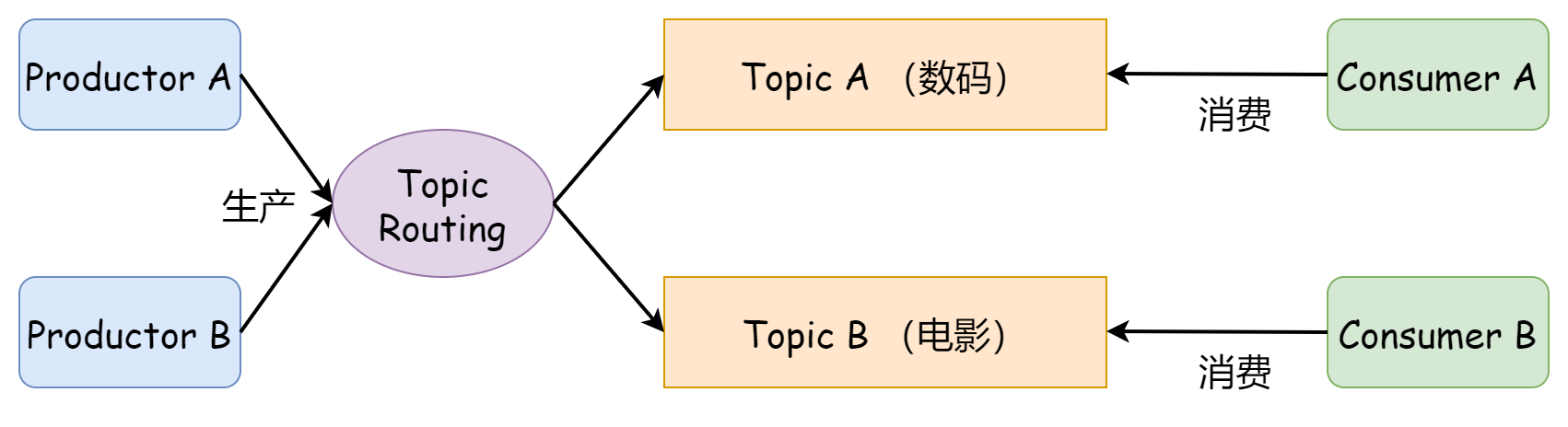
Producer 将消息发送到特定的主题 Topic,Consumer 通过订阅特定的主题 Topic 来消费消息。
并非所有的消费者都想要全部的消息,消费者只对自己感兴趣的 Topic 进行订阅,从指定的 Topic 来获取消息。
这个发送问题由 生产者 Product 来解决,生产者在发送消息时,对消息进行逻辑上的分类,将消息发送到指定的 Topic。(发布-订阅模型)
offset
多个消费者可能对同一个主题感兴趣,即多个消费者 Consumer 订阅同一个主题 Topic。
这个消费问题由 消费者 Consumer 来解决。
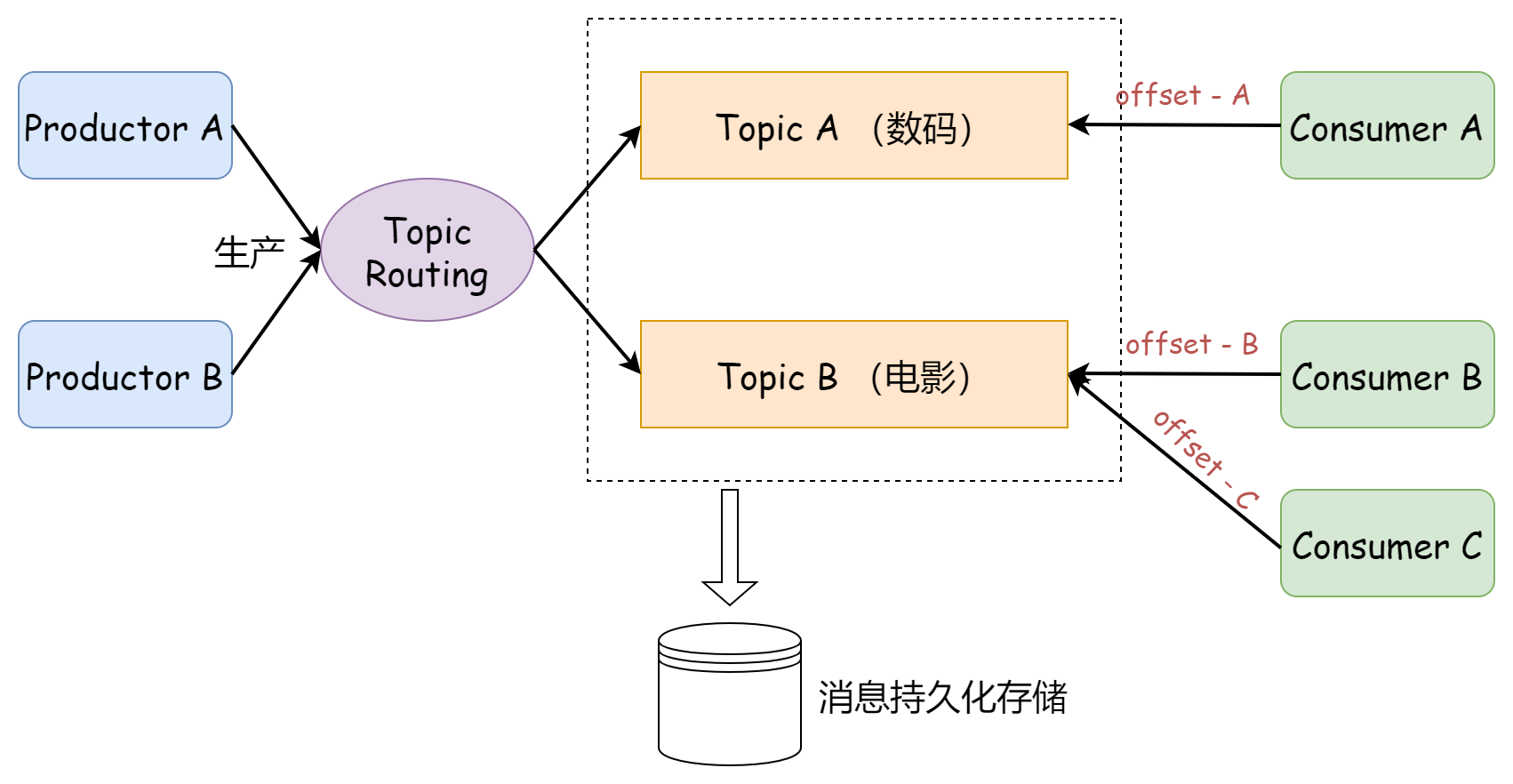
Kafka 将所有的消息进行持久化存储,让消费者各取所需,想取哪个消息,想什么时候取都行,只需要传递一个消息的 offset 即可。
Kafka 将消息以消息日志的方式追加写在磁盘中(顺序磁盘 IO)。
offset 表示了消费者的消费进度。每一条消息都会根据时间先后顺序有一个递增的序号,用 offset 来表示消费者的消费进度到哪了,每个消费者会都有自己的 offset。
每次消费消息的时候,都要提交这个 offset,Kafka 可以选择「自动提交」或者「手动提交」。
Partition
Partition 是 Kafka 「最基本的部署单元」。
对于海量数据,单机的存储容量和读写性能肯定有限,一种常见的存储方案就是「对数据进行分片存储」。
例如在 MySQL 中,单表的数量达到几千万、上亿时,会进行分库、分表操作
例如在 Redis 中,当单个实例的数据量达到几十G引发性能瓶颈时,会进行分片集群
在 Kafka 中,同样采取了水平拆分的方案,将拆分后的数据子集称为 Partition 分区。各个分区的数据集合即为全量数据。
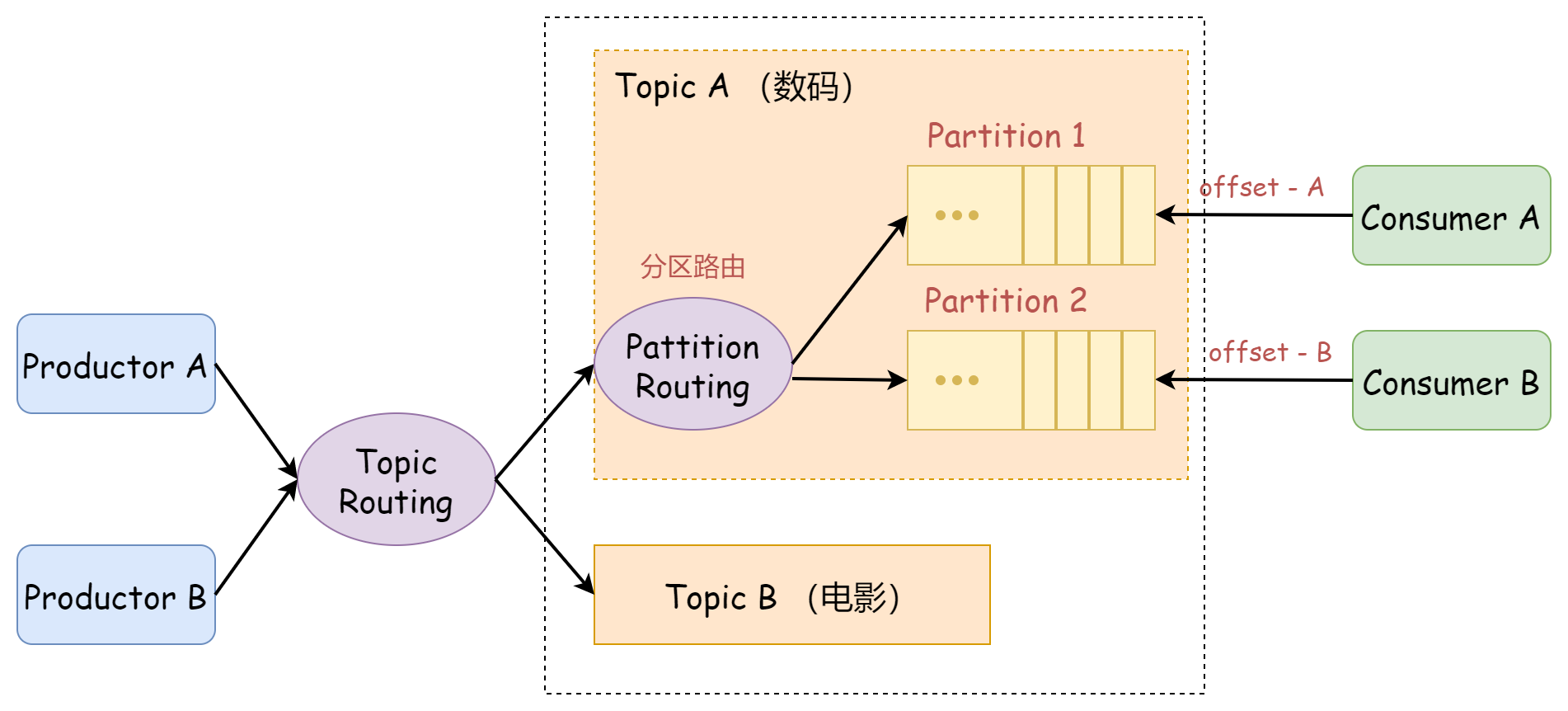
分区路由可以简单地理解为一个 Hash 函数,生产者在发送消息时,可以自定义这个函数的规则决定发往的分区。将分区规则设计的合理,可以将消息均匀地分配到不同的分区上。
生产者 Productor 发送一条消息,先通过 Topic 对消息进行逻辑分类,在通过 Partition 进一步做物理分片,最终多个 Partition 会均匀地分布在集群的每台机器上,从而很好地解决了存储扩展性问题。
Broker
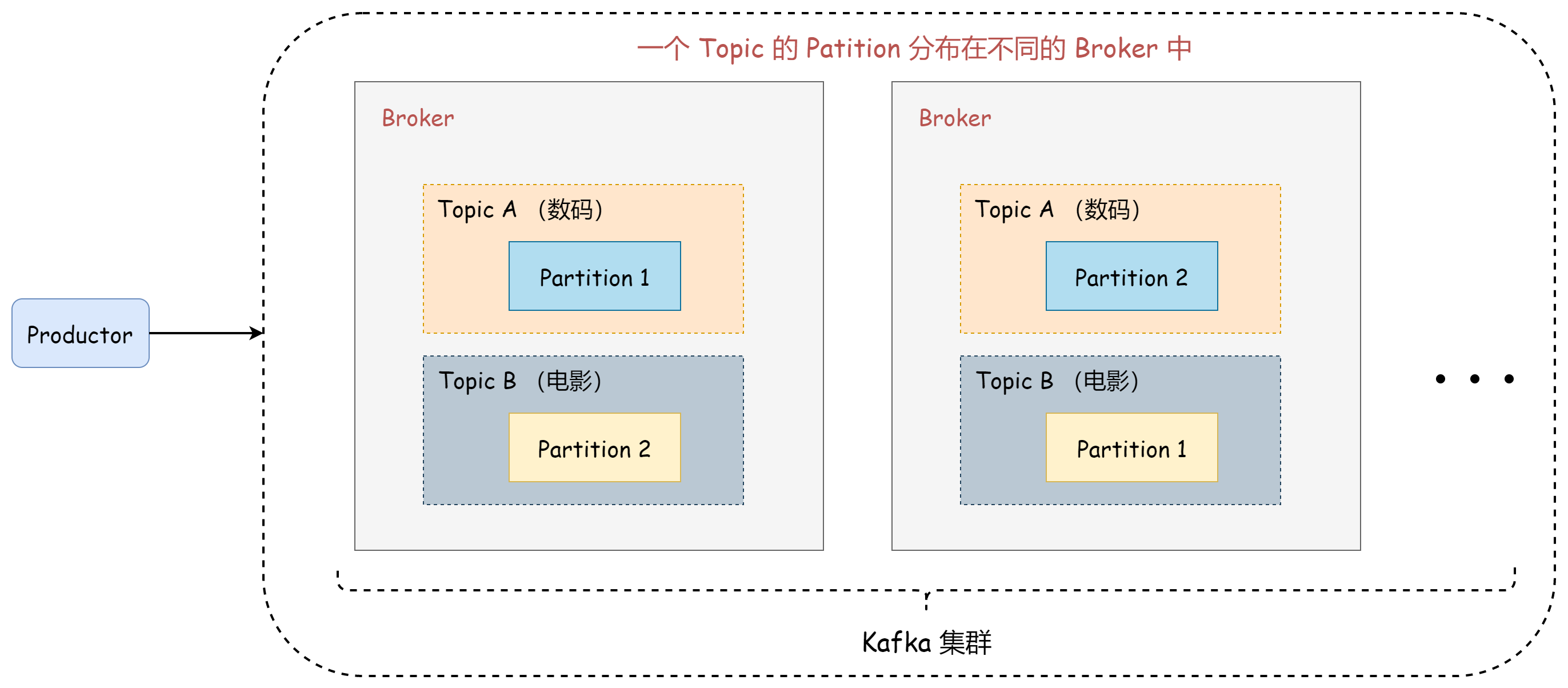
一台 Kafka 服务器被称为 Broker,Kafka 集群由多台 Kafka 服务器组成。
Kafka 是「天然分布式」的。
一个 Topic 会被分为多个 Partition,这些 Partition 会分布在不同的 Broker 中。
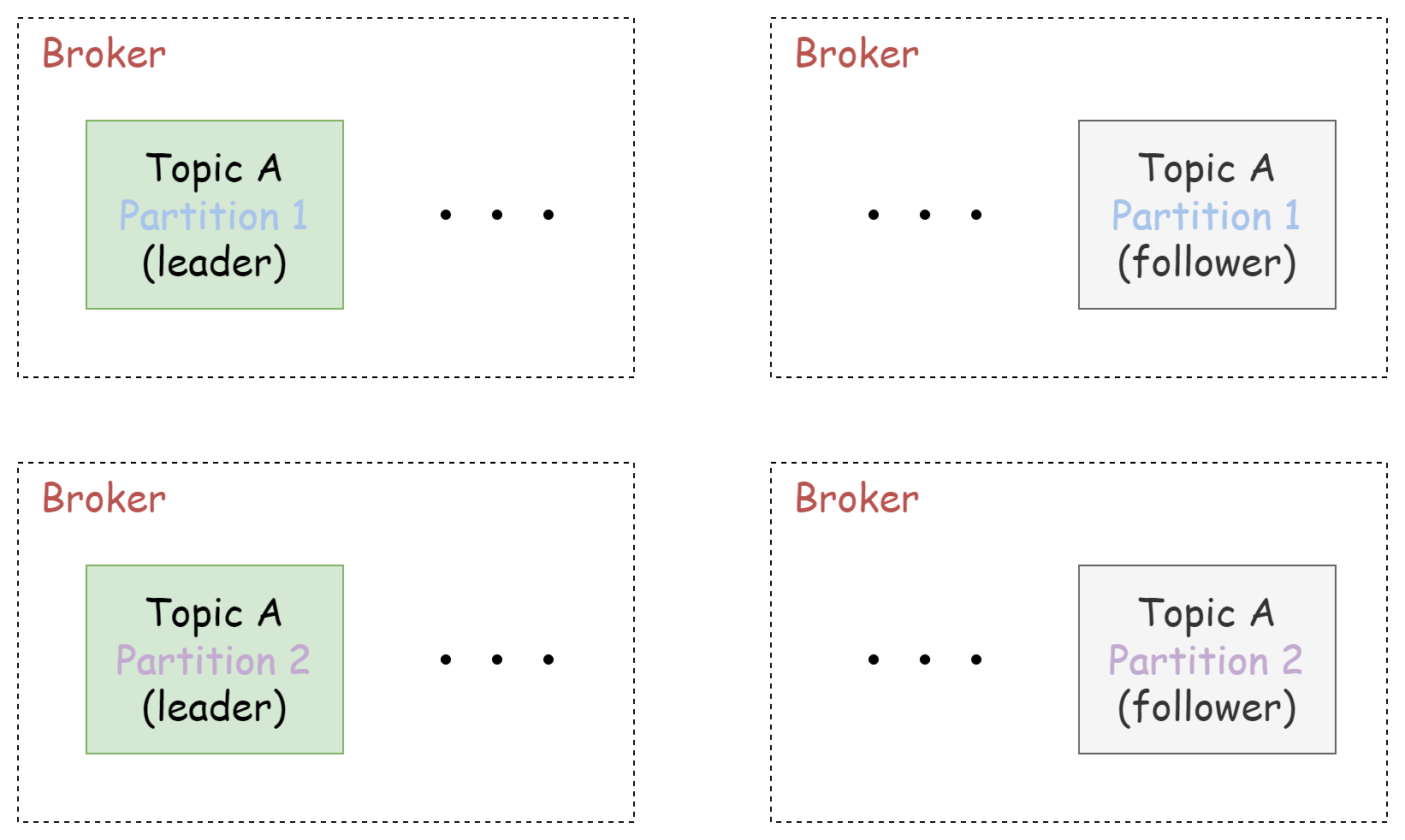
leader & follower
在 Kafka 集群中,每台机器都会存储一些 Partition,为了防止机器宕机时,这部分数据无法访问的问题(持久化保证数据不丢失)。 需要 Kafka 具备故障转移能力,当某台机器宕机后,能够继续保证服务可用。
与 Reids Cluster 类似,Kafka 通过「Partition 多副本」的方式,解决了高可用问题。 在 Kafka 集群中,每个 Partition 都有多个副本,保存了相同的信息。
副本之间是 「一主多从」的关系:
leader副本负责读写数据follower副本负责同步消息,只负责待命
当 leader 副本发送故障时,选举 follower 副本成为新的 leader 对外提供服务。
Consumer Group
Kafka 是个高并发的系统,消息的拉取同样是并行的,多个消费者去消费 Topic 消息。
Kafka 引入了消费者组 Consumer Group 的概念,每一个消费者都有一个对应的消费者组。组间进行广播消费,组内进行集群消费。同时限定:「每个 Partition 只能由消费者组中的一个消费者进行消费」。
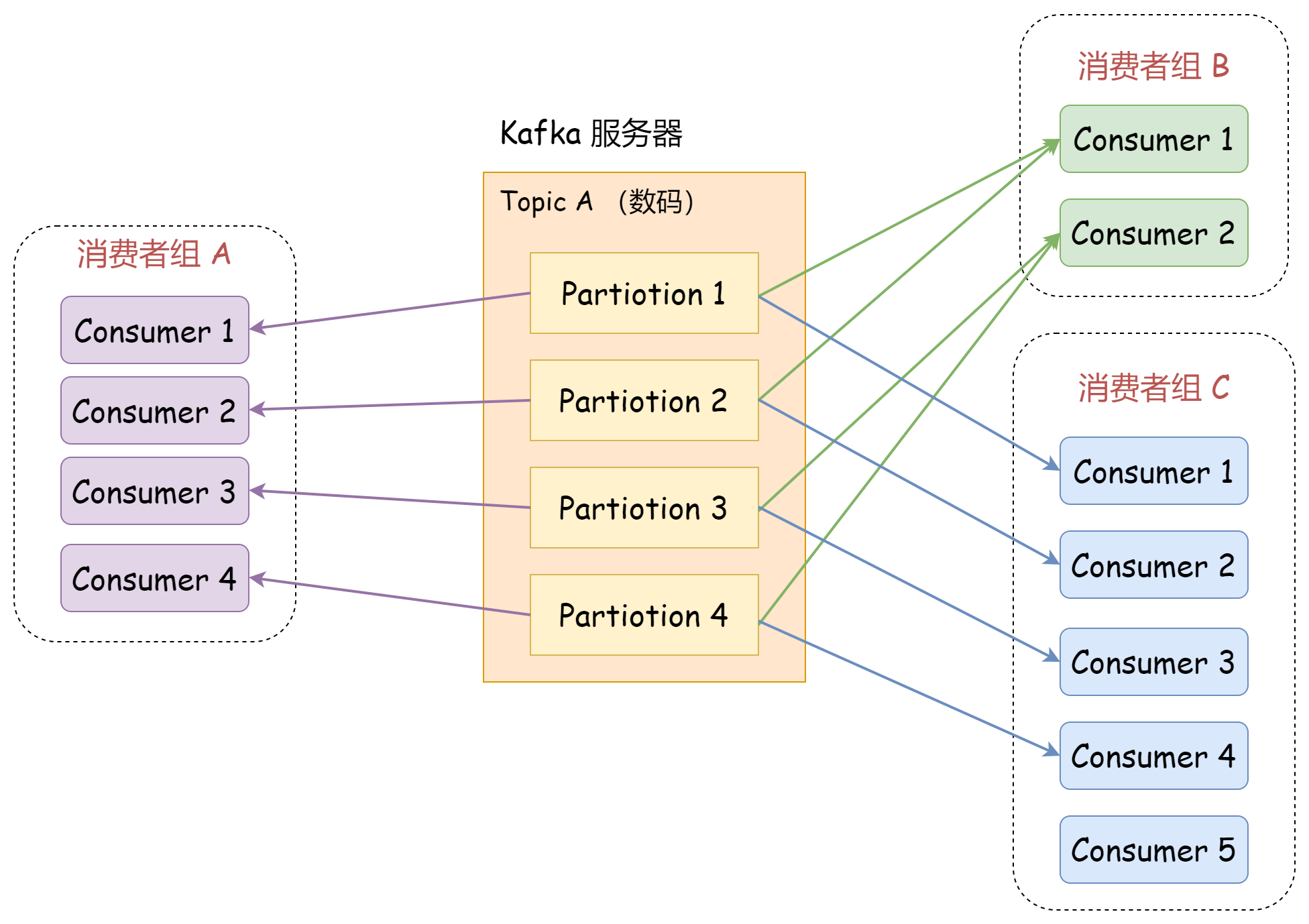
当需要加快消息的处理速度,(如消费者组B)只需要增加新的消费者即可,Kafka 会以 Patition 为单位重新做负载均衡。
一个消费者组可以消费 Topic 的全部数据,消费者组在逻辑上是相互独立的。
🗳️ 存储结构
Kafka 使用「日志文件 Logging」的方式来存储消息;使用「稀疏哈希索引」来加快查询。
Kafka 存储的主要是消息流(文本、自定义格式),对于 Broker 来说,只需要关注消息的投递,无需关注内容本身
写入方面,数据量级非常大,都是按顺序写入(队列),且无需考虑更新
需求简单,只需要按照 offset 查询消息即可
在为了满足其写入需求(量级大、不更新),采用 Append 追加日志的方式最理想,可以充分利用「磁盘顺序 IO」。
在查询时,只需要通过 offset 定位消息,在内存中维护了一个「从 offset 到日志文件的偏移量」的映射关系,每次 查询时,先根据 offset 找到日志文件的偏移量,即可快速读取到日志消息。
为了避免哈希索引常驻内存消耗过多空间的问题,将消息划分为若干个块 block,每个索引需要定位 block 块中的第一条消息的 offset 即可(稀疏索引), 然后在 block 中顺序查找。

🔥 Kafka 的高性能
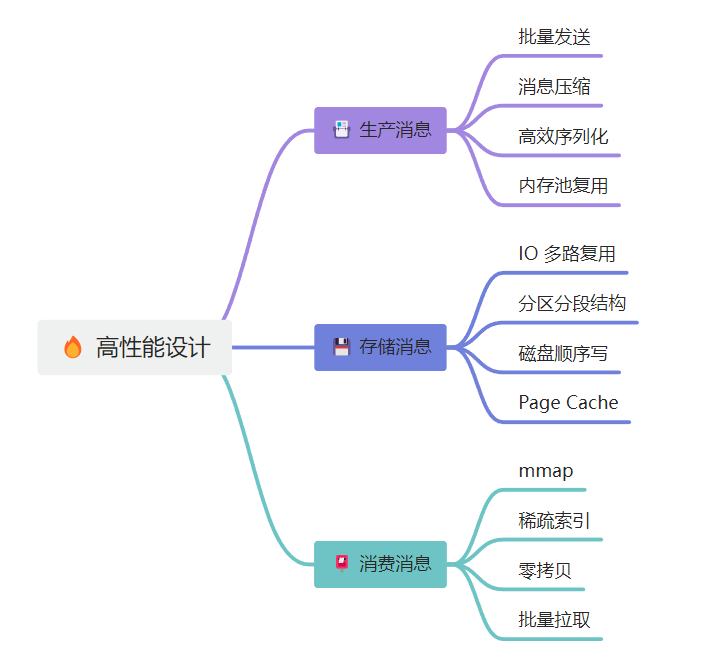
📑 生产消息
Kafka 客户端与传统的数据库或消息中间件不同,在将消息发送给 Broker 之前,在 Client 端先完成大量的工作之后才发送消息,分摊 Broker 的计算压力。
🫧 批量发送
Kafka 通过对多条消息按照分区进行分组,每次发送一个消息集合,从而减少网络传输的开销。
🫧 消息压缩
在批量发送的前提下,对消息进行压缩(数据量越大,压缩效果更好)。同时对多条消息进行压缩,能大幅减少数据量, 同时减少网络、磁盘IO开销。消息持久化到 Broker 的磁盘时,依旧是压缩状态,最终是在 Consumer 端进行解压。
🫧 高效序列化
Kafka 的 Key 和 Value,都支持自定义类型,只需要提供相应的序列化和反序列化器即可。可以根据情况选取对应的序列化方式。
🫧 内存池复用
Kafka 提出了「内存池机制」,提高复用,减少频繁的创建和回收。(本质上与连接池、线程池一样)。
Productor 在创建时,会占用一块固定大小的内存区域,划分为若干个块(例如 16KB)。当需要创建一个新的发送 Batch 时,直接从内存中取出一个块, 从中不断地写入消息(写满或到指定阈值时间时),将这个 Batch 发送给 Broker,之后内存块就会回到缓存池中继续复用。 不会涉及 JVM 的内存回收,以应对 Kafka 的高并发场景。
📇 存储消息
🫧 IO 多路复用
使用
1个Acceptor线程,处理新的连接;使用N个Processor线程,读取请求;使用M个Handler线程,处理业务逻辑。1个Acceptor线程:用于监听网络套接字,接受请求,然后将请求派发给 Processor 线程池中的一个线程来处理。 与 Redis 相同,IO 多路复用允许内核中同时管理多个 scoket 连接,内核会一直监听这些连接,一旦有请求到达,就会通知处理线程,达到一个线程处理多个请求的效果。N个Processor线程:Kafka 会维护一个线程池,将请求分发给可用的 Processor 线程处理。主要负责从套接字读取消息,解析处理,并将响应发送给客户端。达到批量操作,提高吞吐量。M个Handler线程:维护的线程池,负责读取 Kafka Topic 中的消息,并将其提交到对应的 Consumer Group。🫧 磁盘顺序 IO
Kafka 采用日志文件的方式持久化日志,以 Append Only 的方式追加到文件末尾,顺序 IO 使写入速度非常快。
🫧 Page Cache
利用了操作系统本身的缓存技术,在读写磁盘文件时,其实操作的都是内存,由操作系统决定什么时候将 Page Cache 中的数据真正刷入磁盘。
Page Cache 缓存中保存的是最近可能被使用的磁盘数据,具有时间局部性(最近访问的数据可能再次访问)和 空间局部性(访问的数据的周边数据被访问的概率极高)。 作为顺序写入的消息队列,如果生产和消费地特别快,利用 Broker Page Cache,甚至可以不经过磁盘完成操作。
🫧 分区分段结构
Kafka 的 Topic 会被分区为多个 Partition,在多台 Broker 中,使用多个服务来接受消息。
同时每个分区 Partition 会被分为多个段 Segment 来管理,每个段内都是顺序写,避免分区过大,利于管理。
📮 消费消息
🫧 稀疏索引
Kafka 查询场景非常简单,按照 offset 查询消息即可。为了加快读操作,只需要在内存中维护一个 offset 到日志文件的偏移量的映射关系
Map即可。 每次查找消息,先从哈希表中查到文件偏移量,再去读日志文件。🫧 mmap
memory mapped files采用 mmap 映射索引文件,加快索引的查找过程。将磁盘文件与内存虚拟地址做了映射,不需要操作磁盘IO,进程可以使用指针的方式操作这一块内存,系统会自动将脏页写入到对应的磁盘文件上。
🫧 零拷贝
采用了零拷贝,将数据从内存中的缓存区直接拷贝到网卡设备,无需经过应用程序,减少了数据的拷贝和内核态与用户态的切换。
🫧 批量拉取
与发送消息对应,消费消息也是批量拉取的,每次拉取一个消息集合,减少网络的开销。
参考
- https://mp.weixin.qq.com/s?__biz=MzU2MTM4NDAwMw==&mid=2247490102&idx=1&sn=68d55b3c5ac74038c76d6837b862a11c&chksm=fc78c51acb0f4c0cd5a1d6ceedb9948f82d48791ab789e9edfd6e83e34fbad1ace5749bee203&scene=21#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MzU2MTM4NDAwMw==&mid=2247490102&idx=1&sn=68d55b3c5ac74038c76d6837b862a11c&chksm=fc78c51acb0f4c0cd5a1d6ceedb9948f82d48791ab789e9edfd6e83e34fbad1ace5749bee203&cur_album_id=1763234202604388353&scene=189#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MzU2MTM4NDAwMw==&mid=2247491055&idx=1&sn=14bc485f91ec2629cc9e8bf7a36ad8f4&chksm=fc78c2c3cb0f4bd566d5ca2534805839420ad3dc67210bc8f2b7ef05283785b02b8ddef640a8&cur_album_id=1763234202604388353&scene=189#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MzU2MTM4NDAwMw==&mid=2247491168&idx=1&sn=bd37f96692b3f7cecdaf3172abdb7a8c&chksm=fc78c14ccb0f485a451f70c7ffbf5b05d0f500dfef6321703e7cdebdc0de902d9d77a547d469&cur_album_id=1763234202604388353&scene=189#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MzU2MTM4NDAwMw==&mid=2247491507&idx=1&sn=f1bec356c94cd0101809dc11dcf27ba2&chksm=fc78c09fcb0f49898f6cc9b80499aeb871a80f95ab4fbe12c32567cab6a3521a6c33b61dd807&cur_album_id=1763234202604388353&scene=189#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MzU2MTM4NDAwMw==&mid=2247491763&idx=1&sn=cc60a6ba13e5cf4384e623819c621e0d&chksm=fc7b3f9fcb0cb6897be67103d91854831b71909c0d12385fb52b2f1d011fca5d1844b3892019&cur_album_id=1763234202604388353&scene=190#rd