事务
数据库事务
事务(单数据库的本地事务)是指一组操作,要么全部正确执行,要么全部不执行。
事务通常会有 ACID 四大特性:
A原子性C一致性I隔离性D持久性
分布式事务
现在的大型业务系统通常都由若干个子系统构成,这些子系统各自拥有独立的数据库,一个业务流程需要由多个子系统共同完成,这些操作需要要么全部成功,要么全部失败。
分布式事务就是要保障不同数据库数据的一致性。
例如:在大型的电商系统中,下单时会:扣减库存,减优惠,生成订单id等多个步骤,通常订单服务与库存、优惠、订单id都是不同的服务。 这些操作是否成功,依赖于多个系统的结果,可能涉及三个系统服务,三个数据库。所以需要在数据库与应用程序之间,通过“中间”方案,实现分布式事务的支持。
一致性
🚑 强一致性
在任意时刻,所有节点的数据都是一样的,每一次读操作,都能获取到数据最近的一次写操作。
🚚 弱一致性
数据更新后,能够容忍后续的访问只能访问部分数据或全部访问不到。
🚛 最终一致性
不保证任意时刻任意节点上的同一份数据都是相同的,但是在一段时候之后,节点的数据最终会达到一致的状态。
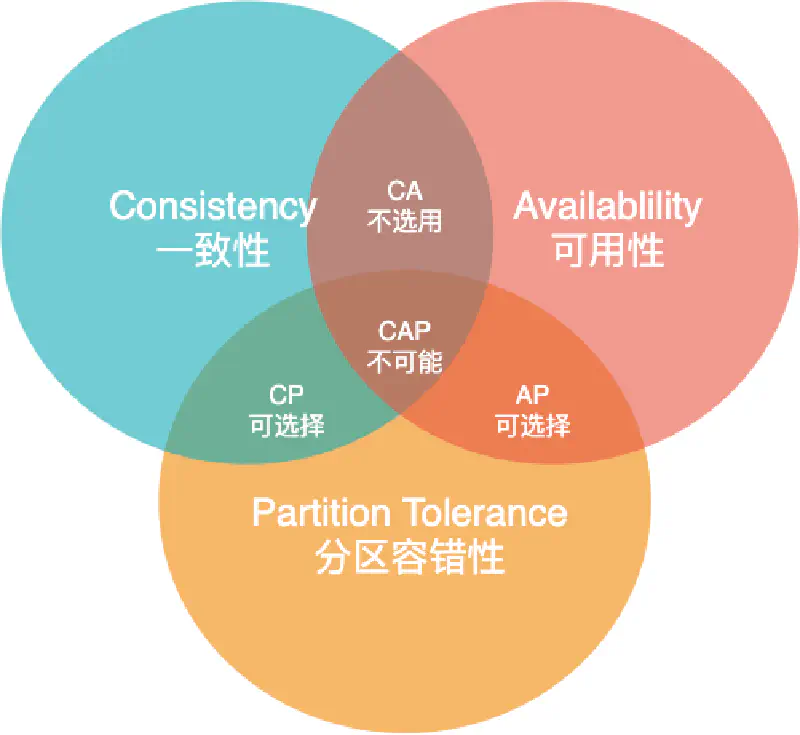
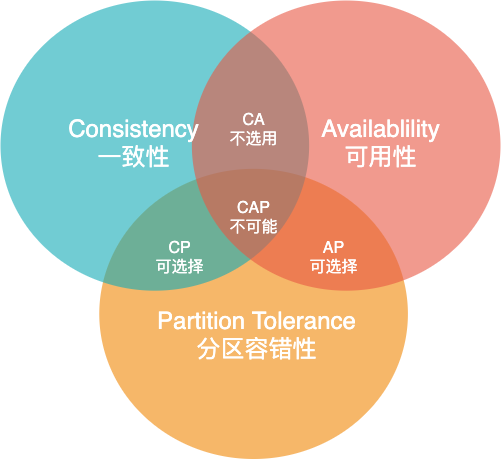
⚙️ CAP
CAP 定理指一个分布式系统中,一致性 Consistency,可用性 Availability,分区容错性 Partition tolerance,「最多只能满足两项」。
C - Consistency一致性所有节点在同一时间的数据完全一致。(任意时间在任意节点访问到的都是最新的数据)
A - Availability可用性服务在一定时间内,都会返回一个明确的结果,服务一直可用。
P - Partition Tolerance分区容错性一个服务分布在不同的系统中,如果部分系统宕机,其他系统能够继续提供服务。
🅿️ 分区容错性时分布式系统的根本,如果分区容错性不能满足,那使用分布式式系统将失去意义。
CP
一致性 & 分区容忍性
优先保障数据的一致性。
如涉及金钱交易的环节,保障数据不能出错。
AP
可用性 & 分区容忍性
优先保障系统的可用。
互联网中大多数场景都是保障系统可用,如在有大量请求时,一些服务可以先不提供,如在双十一活动时,限制用户查询历史账单。
🫧 BASE
BASE 理论是指:
BA - Basically Available基本可用分布式系统出现故障的时候,允许损失部分可用性,保证核心可用。
S - Soft State软状态允许系统存在中间状态,这个中间状态不会影响系统整体的可用性。
E - Eventual Consistency最终一致性系统中所有的数据副本经过一定时间后,最终能够达到一致性的状态。
BASE 理论本质上是对 CAP 理论的延伸,是对 AP 的补充。
对于业务系统来说,通常选择牺牲一致性来换取系统的可用性和分区容错性。但是不是完全放弃数据一致性,而是牺牲强一致性来换取弱一致性,采用合适的方式来保证最终一致性。
分布式事务常见场景
- 银行转账
在银行转账中,扣余额和添加余额需要同时成功。扣减账户余额成功,增加账户余额失败;扣减账户余额失败,增加账户余额成功,都是不允许发生的。
- 下订单和扣库存
下订单和扣库存需要保持一致,如果先下订单,扣库存失败,那么将会导致超卖;如果下订单没有成功,扣库存成功,那么会导致少卖。
- 同步超时
服务化的系统间调用常常因为网络问题导致系统间调用超时,系统A同步调用系统B超时,系统A可以明确得到超时反馈,但是无法确定系统B是否已经完成了预定的功能或者没有完成预定的功能。于是,系统A就迷茫了,不知道应该继续做什么,如何反馈给使用方。
一致性协议
事务管理器 TM - Transaction Manager:负责协调和管理事务,控制着全局事务并管理事务的生命周期,并协调各个 RM。
资源管理器 RM - Resource Manager:事务的参与者,可以指一个数据库实例,通过资源管理器对数据库进行控制,即一个分支事务。
DTP 模型定义 TM 和 RM 之间的通讯接口规范叫做 XA(即数据库提供的 2PC 接口协议),基于数据库的 XA 协议来实现的 2PC 称为 XA 方案。
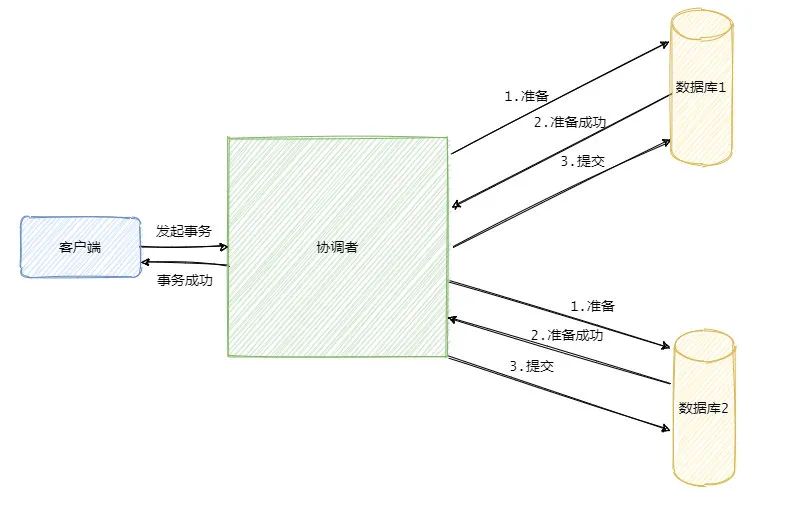
🤲 2PC
两阶段提交(2PC)把分布式事务分为两个过程:准备阶段 Prepare,提交阶段 Commit / 回滚阶段 Rollback。
第一阶段
prepare执行实际的业务操作,但不提交事务,锁定资源。
事务管理器(TM,Transaction Manager)向所有本地资源管理器(RM,Resource Manager)发起请求,询问是否是就绪 ready 状态,所有的参与者都将本地事务能否成功的信息反馈给协调者。
第二阶段
commit / rollback事务管理器根据所有本地资源管理器的反馈,通知所有本地资源管理器,步调一致地在所有分支上提交或回滚。
只要有一个 RM 失败,就会进行回滚操作;否则通知所有 RM 提交事务。提交事务后释放锁资源。
⚒️ Seata 实现 2PC
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
📇 Seata 把一个分布式事务理解成一个「全局事务」和若干「分支事务」:
全局事务:协调各个分支事务达成一致
分支事务:可以理解为一个关系数据库的本地事务
🗃️ Seata 定义了三个组件处理分布式事务:
TC(Transaction Corinator)事务协调器
独立的中间件。
维护全局事务的运行状态:接收 TM 指令发起全局事务的提交与回滚;负责与 RM 通信协调各个分支事务的通知与回滚。
TM(Transaction Manager)事务管理器
jar包。
嵌入应用程序中工作,负责开启一个全局事务,最终向 TC 发起全局提交或全局回滚。
RM(Resource Manager)资源管理器
控制分支事务。
接收 TC 的指令,驱动本地事务的提交或回滚。
📺 在架构方面,2PC 方案的 RM 实际上是在数据库层面,RM 本质上是数据库自身通过 XA 协议实现;seata 中 RM 以 jar 包的形式作为中间件层部署在应用程序一侧。
🗳️ 在两阶段提交方面,2PC 在第二阶段决议 commit / rollback,事务性资源锁要保持在第二阶段完成后释放;seata 在第一阶段就将事务提交,省去第二阶段持有锁的时间,提高整体效率。
配置 Seata 服务
- 启动 seata 中间件服务
- 配置服务注册中心
- 在应用配置 regsitry.conf、file.conf(在 seata 中拷贝)
- 使用 seata 服务,需要在双方数据库中创建
undo log表1 2 3 4 5 6 7 8 9 10 11 12 13CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) NOT NULL, `context` varchar(128) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
创建代理数据源
每个 RM 通过 DataSourceProxy 使用代理连接。与 TC 进行通信交互、记录 undo_log 等。
第一阶段业务操作生成对于的 undo_log,将 undo_log 和业务数据放在一个本地事务提交(undo_log 记录了修改前的值,同时提交后释放锁资源)。
TM 开启全局事务,会将全局事务ID XID 放在事务上下文中,并通过远程调用传入下游的各个分支事务。
第二阶段(1)事务提交,TC 通知各个分支完成事务,只需要删除对应的undo_log(第一阶段已经分支提交);(2)事务回滚,通过 XID 和 Branch ID 找到对应的 undo_log 生成反向 SQL 执行即可。
| |
双方业务实现
@GlobalTransactional 开启全局事务。GlobalTransactinalInterceptor 会拦截 @GlobalTransactional 注解的方法,生成全局事务IDXID。
XID 会在整个分布式事务中传递,在远程调用时 spring-cloud-alibaba-seata 会拦截 Feign 调用将 XID 传递到下游服务。
| |
| |
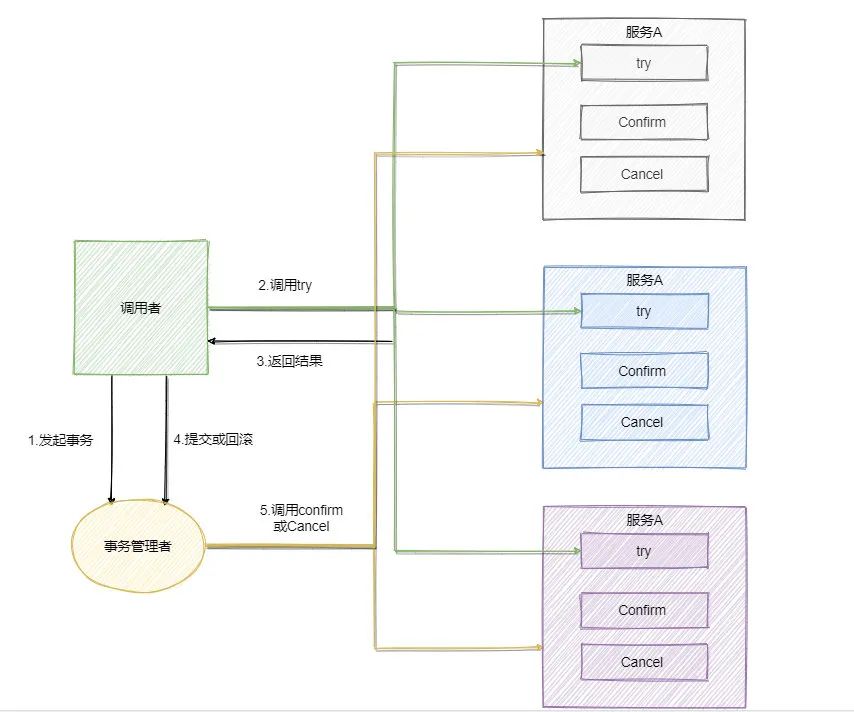
🛍️ TCC
TCC Try - Confirm - Cancel
TCC 由支付宝团队提出,被广泛应用于金融系统中。我们用银行账户余额购买基金时,会注意到银行账户中用于购买基金的那部分余额首先会被冻结,由此我们可以猜想,这个过程大概就是 TCC 的第一阶段。
T - Try阶段尝试执行。完成所有的业务检查,「预留必须的业务资源」。
是对业务系统进行检查和资源预览,如订单和存储操作,需要检查库存剩余数量是否可用,并进行资源预留。
C - Confirm阶段确认执行真正的业务。该阶段不会做任何业务检查,只使用 Try 阶段预留的业务资源。
在 TCC 中,通常认为 Try 阶段成功后,Confirm 一定会成功,如果 Confirm 阶段出错,需要进行重试。
C - Cancel阶段取消执行。释放 Try 阶段预留的业务资源。
在 TCC 中,认为 Cancel 一定会成功,如果失败,需要重试。
基于 TCC 实现分布式事务,需要将业务上的每一个实现逻辑拆分为 Try、Confirm、Cancel 三个部分,相对来说代码实现复杂度较高,对业务的侵入较大和业务紧耦合。
分布式解决方案
可靠消息最终一致性
可靠消息最终一致性是指在分布式系统中,通过异步消息传递实现数据的一致性。
每个节点都可以独立地进行操作,「发起方」执行完本地事务后,将操作的结果作为「消息」发送出去; 这些消息可能会有延迟、重复、丢失等; 但最终「事务参与方」一定能接受到消息,并成功处理事务,使得数据状态「最终」达到一致。
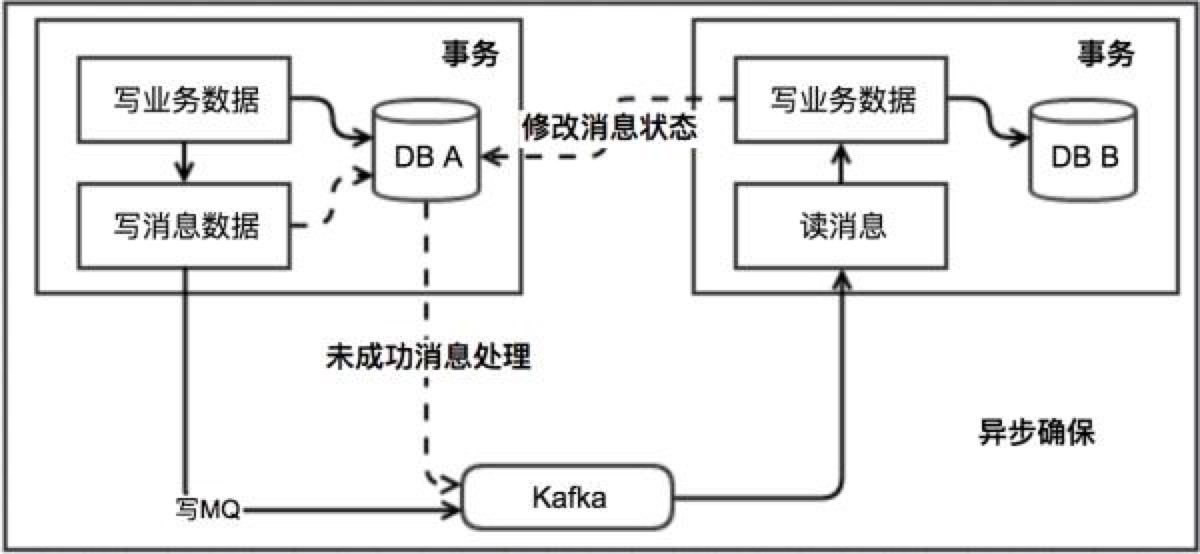
🐬 本地消息表方案
利用了「各系统的本地事务」来实现分布式事务。
在业务相关的同一个数据库中,创建一张「本地消息表」,⚙️ 执行业务相关操作 & 📋 记录消息到消息表放在同一个事务中。
后台任务定时扫描本地消息表,将未确认的消息,发送给目标节点/消息队列。(失败重试)
目标节点接收到消息后,可以将消息写入「本地消息表」(可用来判重、是否成功处理消息), ⚙️ 执行相关业务操作 & 📋 记录表信息 & 👌 返回 ACK 操作放在同一个事务中。
如果目标节点中的本地事务失败,会一直不断重试。如果时业务失败,会向源系统发起回滚。
最大努力通知
可靠消息最终一致性关注的是业务过程中的事务一致,以异步的方法完成业务。(消息可靠性由发起方保障)
最大努力通知关注的是业务完成后的通知事务,将执行的结果可靠的通知出去。
发起通知方通过一定的机制,尽最大的努力将消息处理的结果通知到接收方,如果通知失败,发送方会不断地进行超时重试,如果一直不能通知到,接收方会主动查询发送方的接口(消息的可靠性由事务的被动方保障)。
最常见的场景就是支付回调,支付服务到第三方支付成功后,第三方支付会有回调通知,如果回调失败,会通过一定的频率重试,并且第三方支付会提供主动查询支付状态的接口。既有回调通知,也有交易查询接口。